Самая лучшая система распознавания текста
ABBYY FineReader 8.0
Самая лучшая система распознавания текста на данный момент. Позволяет пользователю автоматизировать процесс сканирования, с легкостью распознавать книжный тексти сохранить текст и сканированные изображения в различные форматы. Так же с ее помощью возможно удобное создание электронных книг.
Данный комплекс можно скачать по следующим адресам:
Программа - http://fr7.abbyy.com/fr80/FR80PE_TB_ER.exe
Доп. языки распознавания - http://download.abbyy.com/addlang/build800706/default.aspx?language=en
Русский интерфейс - http://fr7.abbyy.com/fr80/addlang/8.0.0.706/Russian%20UI/Russian%20UI.exe
Вопросы по регистрации и др. - http://forum.ru-board.com/forum.cgi
Данная программа предназначена для создания
Данная программа предназначена для создания DjVu файлов.
DjVu - графический формат, оптимизированный для хранения отсканированных документов. В частности он идеально подходит для создания электронных книг.
Особое значение этот формат приобретает для переноса в сеть математической и вообще технической литературы, где обилие схем и формул делает распознавание и перевод в текстовый формат практически невыполнимым. В настоящее время DjVu становится фактическим стандартом для электронных библиотек технической и научной литературы.
Данный комплекс можно скачать по следующим адресам:
Программа
Без поддержки распознавания, виртуального принтера идр (каждый файл не более 1.5 Mb)
Document Express Editor v6.0.1 Build 1320 LE NT - http://www.dstu2204.narod.ru/djvu/Editor6_LE_nt.rar
Document Express Editor v6.0.1 Build 1320 LE 9x - Document Express Editor v6.0.1 Build 1320 LE 9x
Полная версия (53.1 Mb)
Document Express Editor v6.0.1 Build 1320 - http://www.lizardtech.co.jp/download/djvu/modules/windows/editor/6.0.1/ProfessionalEditor.zip
Русификатор http://abab.front.ru/Document_Express_Editor_6.0.1.1320_rus.zip
Более подробно о программах и др, можно узнать на http://www.dstu2204.narod.ru/djvu/
Работа с программой
Краткая инструкция по использованию...
Краткая инструкция по использованию программ ABBYY FineReader 8.0, Document Express Editor 6 для сканирования книг...
Данная инструкция предназначена для людей, которые хотят сэкономить свое время, автоматизируя процесс перевода текстового материала (книг, рукописей и др.) в электронный вид.
Инструкция находится в стадии написания, поэтому все предложения и пожелания направляйте по e-mail.
Содержание:
Краткая инструкция по использованию программ ABBYY FineReader 8.0, Document Express Editor 6 для сканирования книг... ABBYY FineReader 8.0 Работа с программой Шаг 0 (смена языка интерфейса) Шаг 1 (настройка процесса сканирования) Шаг 2 (сканирование) Шаг 3 (Обрезка изображения) - необязательно Шаг 4 (поворот листа) Шаг 5 (распознавание) - необязательно Шаг 6 (проверка после распознавания) - необязательно Шаг 7 (сохранение) Document Express Editor 6 Работа с программой Шаг 1 (открытие файла) Шаг 2 (добавление других файлов вDocument Express Editor проект) - при необходимости Шаг 3 (сохранение) Шаг 4 (распознавание) - необязательно Шаг 5 (печать) - при необходимости
смена языка интерфейса)
Шаг 0 (смена языка интерфейса)
Запускаем программу c помощью "панели задач": "Пуск" --> "Программы" --> "ABBYY FineReader 8.0" --> "ABBYY FineReader 8.0 Professional Edition".
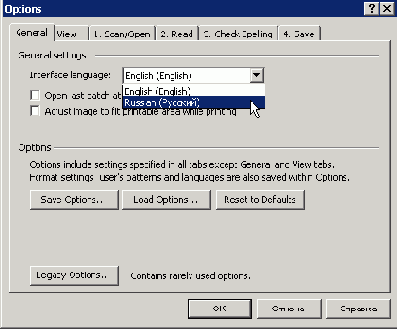
После запуска в верхнем меню с помощью мыши выберите пункт "Tools".

В ниспадающем меню выберите пункт "Options".

После чего установите соответствующий язык интерфейса и нажмите кнопку "OK".
После чего появится окно с информацией, нажимаете кнопку "ОК" и выходим их программы.

настройка процесса сканирования)
Шаг 1 (настройка процесса сканирования)
Нажимаем на стрелку "



Устанавливаем "Использовать интерфейс ABBYY FineReader", "Сканировать несколько страниц" (незабудте, что если вы в дальнейшем будите сканировать малое число страниц убрать эту опцию), "Устранить искажение строк".
После чего настраиваем сам сканер, для этого нажмите на кнопку "Настройки сканера" (иногда после нажатии этой кнопки следует подождать от 5 до 60 секунд), после откроется окно настройки сканера.
Опцию "Определять ориентацию страницы" следует включать, если вы собираетесь распознавать текст, в этом случае вам не придется переворачивать страницы самим. Но следует иметь ввиду, что при работе с технической литературой, изобилурущей различными сложными формулами и сложными схемами..., применять данную опцию бесполезно.

Режим сканирования устанавливайте в соответствии с примером приведенного на картинке (не рекомедруется устанавливать цветное изображение, т.к. это значительно увеличит время сканирования, разрешение сканирование не делайте менее 300 dpi).
"Ориентация изображения" - устанавливайте исходя из источника (книги и т.п.), данный пункт позволит в дальнейшем не переворачивать изображения.
"Пауза между страницами" - если вы сканируете большое количество материала, то желательно отметить именно этот пункт (установите интервал сканирования в пределах 3-10 секунд). Если же страниц 1-10, то лучше выбрать опцию "Останавливаться между страницами", тогда при каждом новом сканировании будет появляться соответствующее окно).
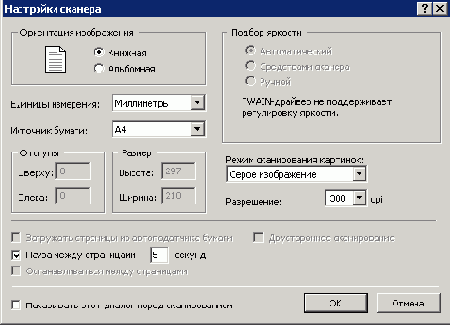
После чего откройте ниспадающее меню "Источник бумаги" и "Выберите пользовательский".

После чего вы сможете выбирать размеры источника (книги и т.п.), предварительно померив книгу... линейкой (задавайте размеры с небольшим запасов (5-10 см).

открытие файла)
Шаг 1 (открытие файла)
Для октрытия файла нажмите на иконку

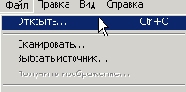
После появится диалоговое окно, в котором необходимо выбрать формат файла (в нашем случае tiif).


добавление других файлов...
Шаг 2 (добавление других файлов вDocument Express Editor проект) - при необходимости
Зачастую вам приходится изготавливатDjVu - файл их нескольких файлов. В этом случае при добавлении новых файлов, вам необходимо выделить страницу после (или до которой) необходимо вставить файл(ы). Для примера вставим еще один любой файл в конец проекта, для этого выделяем последний файл, как показано на рисунке.

После чего в верхнем меню выбираем "Правка" -> "Добавить страницы после", после чего у вас появляется окно аналогичное в 1 шаге, где вы и выбираете нужный файл.

сканирование)
Шаг 2 (сканирование)
Нажимаем на кнопку "Cканировать".

После чего появиться нижние окно.
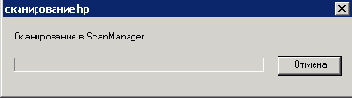
Далее произойдет снова сканирование, что бы его остановить необходимо один раз нажать кнопку "Сканировать" (после чего процесс сканирования завершается через 1-120 сек), а не кнопку "Отмена".
Обрезка изображения) - необязательно
Шаг 3 (Обрезка изображения) - необязательно
Очень часто при сканировании нужно удалить некоторые не нужные части документа (например черные полосы по краям, пустые части и др.) Эту опцию имеет смысл применять если у вас небольшое количество материала ( 1-20 страниц), т.к. обрезка идет вручную (для автоматизации этого процесса необходимо воспользоваться программами сторонних разработчиков).
Так же для того, что бы не было черных полос можно положить белый листок на сканируемый материал или прикрывать крышкой сканера.
Выделите одно необходимое изображение и нажмите "Ctrl+Shift+C" или можно воспользоваться меню (см. рис. ниже).

После чего появится окно, в котором вы сможете указать необходимую область, документа, которая должна остаться. Также можно "привести" изображение с соответствующему формату (A4, пользовательский...).

сохранение)
Шаг 3 (сохранение)
Для сохранения файла нажмите на значок


После чего отмечаем: сохранять страницы "Вместе". Если у вас полная версия программы (дистрибутив более 40Mb), то возможно распознавание текста, для этого поставьте галочку рядом с "OCR" (распознавание текста, точнее вставка текстового слоя можно привести и с помощью программы DjvuOCR, которая работает в комплексе с программой ABBYY FineReader 7). Далее распознавание документа будет расмотренно более подробно в шаге 4.
.
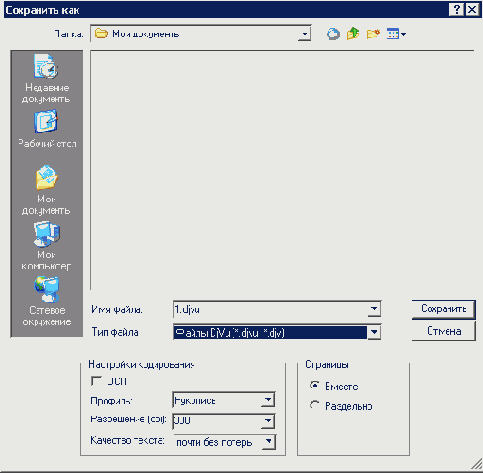
Профиль сохранения:
Названия профиля говорит о его назначении, поэтому особой трудности вызнать это не должно. Но при неправильном выборе можно получить исходный файл плохого качества или большего размера.
Например:
"Нормальный" - в большинстве случаев можно использовать его (в основном для книг, для рукописи использовать не рекомендуется)
"Черно-белый" - выбирайте, если материал хорошего качества, и большая часть - книжный текст (рекомендуется для книг и различный буклетов)
"Рукопись" - подходит для лекций и др.

Разрешение
Чем выше разрешение, тем лучше исходный текст, рекомендуется выбирать 600 dpi (несмотря на то, что сканирование шло при 300 dpi).

Качество текста
В большинстве случаев лучше выбирать "почти без потерь" (если текст в исходном файле получится неудовлетворительного качества, то установите сохранение "без потерь"). Но если вы собираетесь переслать текст, например, для предварительного ознакомления, то можно поставить качество с большими потерями.

Пример файлов (профиль сохранения: черно-белый, качество текста: почти без потерь): 300 dpi и при 600 dpi. Как видно из примера файл с разрешением 600dpi по качеству лечше чем 300dpi, к тому же файл с 600dpi занимает место меньше чем другой (примеры этих файлов).
поворот листа)
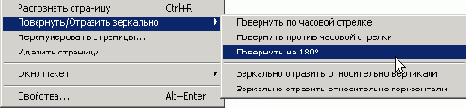
Шаг 4 (поворот листа)
После того как начато сканирования, создается новый пакет, в который и сохраняется вся последующая информация. Ниже приведен пример пакета.

Как видно из примера, вторую страницу необходимо перевернуть, для этого нажмите на нужную страницу правой кнопкой мыши, после чего откроется ниспадающее меню, выберите пункт "Повернуть/Отразить зеркально" и далее поверните соответственно страницу для нормального просмотра.
Для группового выполнения операций нажмите на нужную первую страницу проекта, начиная с которой вы хотите произвести нужные действия, потом зажмите клавишу "Shift" и стрелками вверх или вниз выделите нужные страницы. Так же вместо этого вы можете воспользоваться мышью и по аналогии с выделением нескольких файлов в системе Windows, выделить нужные страницы.
распознавание) - необязательно
Шаг 4 (распознавание) - необязательно
Распознавание так же возможно непосредственно в программе Document Express Editor.
Из верхнего меню: "Сервис"-> "OCR" -> "OCR документа" (также можно указать распознать при сохранении файла, см. шаг 3).

После чего пойдет процесс распознавания текста.

Если в результате распознавания у вас некорректно был выбран язык распознавания (например, текст на русском языке, а распознавание производилось с учетом того, что это был английский, в результате чего оно получилось некорректным).
Для настройки языка распознавания зайдите, как показано на нижних рисунках и выберите соответствующий язык.


печать) - при необходимости
Шаг 5 (печать) - при необходимости
Заключительный процесс распечатка документа.
Иногда бывает, что в исходном файле отчетливо не видно некоторых элементов (например, надпись карандашом). Для того чтобы увидеть и распечатать документы с такими элементами необходимо произвести коррекцию цвета.
Входим в настройки программы (см. рисунок).

Далее отмечаем флажки "Как на мониторе" и "Высококачественная печать". После регулируем любой ползунок (при регулировании одного ползунка, второй автоматически принимает аналогичное положение) для достижения наилучшего качества изображения (чем темнее тем, более отчетливее изображение). Если у вас неполучилось с первого раза, то меняйте данное расположение ползунка для достижения необходимого эффекта.

Для распечатки файла нажмите на значок

В данной работе обрабытывались лекции Семенова П.В. (МГПУ)
Автор: Русинов А.С.
распознавание) - необязательно
Шаг 5 (распознавание) - необязательно
Данную возможность имеет смысл применять, если у вас преобладает обычный книжный текст (нет формул, сложных схем, рисунков с надписями внутри рисунков...) и в дальнейшем будет необходимость копировать или править исходный текст.
Для начала процесса распознавания, необходимо установить язык распознавания. Для этого нажимаем на стрелку "


Далее устанавливаем необходимые языки распознавания, как правило "Русский и английский" вполне достаточно. Но если вы работаете, например, с английским изданием, где не встречает кириллица, то соответственно выбираем только английский язык (данный шаг позволит ускорить процесс распознавания). После чего нажимаем кнопку "ОК".

Далее нажимаем кнопку "Распознать".

Для распознавания сразу всех страниц необходимо нажать на сочетание клавиш "Ctrl+Shift+R" или нажимаете на стрелку "


проверка после распознавания) - необязательно
Шаг 6 (проверка после распознавания) - необязательно
Данный раздел будут добавлен позже
сохранение)
Шаг 7 (сохранение)
Для последующего этапа создания электронной книги... вам необходимо сохранить страницы в формате TIFF. Выберите соответствующий пункт из верхнего меню (см. рис. ниже) или нажмите сочетание клавиш "Ctrl+Alt+S".
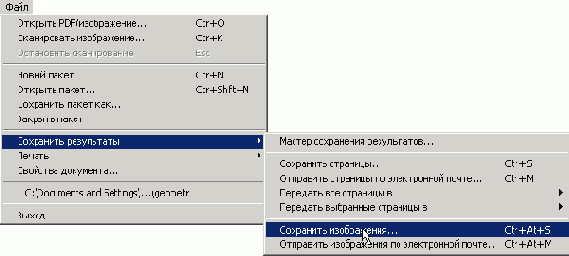
Далее устанавливаем сохранить все страницы в один файл (как на рис.).

В ниспадающем меню выбираем "TIFF, серый, несжатый (*.tif)" (помните, что у вас должно быть достаточно места, т.к. данный файл занимает много места, в среднем для обычной тетради необходимо 1000 Mb). Если у вас мало места на диске, то можно сохранить (но все же не желательно, т.к. качество будущей книги... может быть ухудшено) в формат "TIFF, серый, сжатие: JPEG (*.tif)".

После чего сохраняете в tiff файл.
Если у вас распознанный документ, то можно сохранить данные... в различные текстовые форматы. Для этого нажмите сочетание клавиш "Ctrl+S" или как выше через меню файл выберите "Сохранить страницы".
После сохранения изображения не забудьте сохранить сам проект в "пакет" (сохраняйте, если захотите продолжить проект в будущем; а также после 100 отсканированных страниц, во избежание порчи проекта).
Из меню файл, выбираем пункт "Сохранить пакет как".

После чего выбираем имя и сохраняем
